
Downloading your own copy of Facebook's LLaMA (GPT-3 Competitor)

2023 is starting to shape up to be an incredible year already! We are just 2 complete months in, and AI has exploded into the eyes of humanity! Creating models such as GPT-3, ChatGPT (see RLHF) and even LLaMA.
Sadly enough for us, OpenAI decided not to release their trained model (which makes sense seeing the price point it takes to train such a model obviously). But, luckily for us, Facebook things differently about them
This is why I admire Facebook for AI. Yann LeCun always stated that open sourcing AI allows Facebook to attract and retain top talent in the field, because Facebook is then seen as the leader in its field.
Introduction
Seeing the sensitiveness of these large language models and what they can do in terms of harm in the AI community, Facebook decided to only release the LLaMA model once you get access to it through a form.
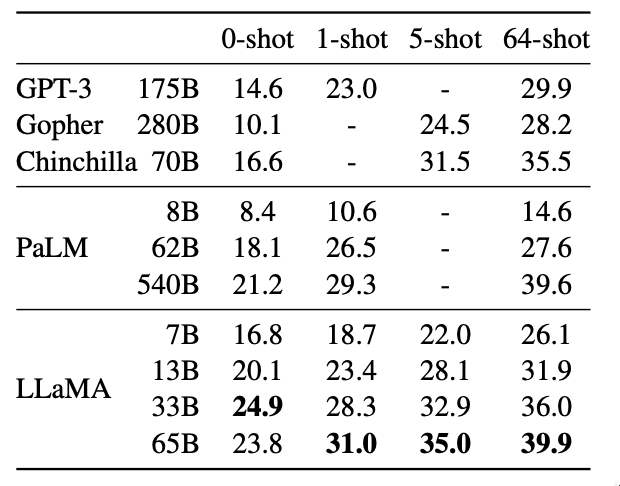
LLaMA should perform even better than GPT-3 according the the results in its paper!
Most notably, LLaMA-13B outperforms GPT-3 while being more than 10× smaller, and LLaMA-65B is competitive with Chinchilla-70B and PaLM-540B.
Now - as the nature of the internet is - some people found out that Facebook released the model in a commit to shortly able remove it again. They however forgot to disable the torrent, so people downloaded it and reuploaded it.
Downloading it yourself
Let's get started to download this. On GitHub we can find a repository by Shawn Presser, who created a script to download the model
 shawwn
shawwnTo run this, we can simply use the following CLI commands:
# Linux
curl -o- https://raw.githubusercontent.com/shawwn/llama-dl/56f50b96072f42fb2520b1ad5a1d6ef30351f23c/llama.sh | bash
# Mac
brew install md5sha1sum
brew install bash
curl -o- https://raw.githubusercontent.com/shawwn/llama-dl/56f50b96072f42fb2520b1ad5a1d6ef30351f23c/llama.sh | $(brew --prefix)/bin/bashIf we naively run this, we would only use our local internet line to download it. Next to that, when we want to infer such a model, we won't have a strong enough GPU to run it seeing the size of it. Therefore, let's work with an intermediary step that downloads the model to an Azure Storage Account! This account we can then later attach to a virtual machine or Azure Machine Learning workspace to infer from and create our own endpoint.
Downloading at Speed with Azure
To download at speed, we need to execute a few steps:
- Create a resource group
- Create a Virtual Machine
- Install the requirements on our VM (`azcopy`)
- Generate a SAS token to the destination azure storage account
- Download the file from the shell script
- Reupload the file with azcopy
You need to have a storage account already where you want to save the output model!
Let's script this out:
Note: replaceYOUR_SUBSCRIPTION_ID,YOUR_EXISTING_SA_NAME,YOUR_EXISTING_SA_CONTAINER_NAMEandYOUR_PASSWORDwith the names you prefer.
#!/bin/bash
# Note: On mac, install sshpass with `curl -L https://raw.githubusercontent.com/kadwanev/bigboybrew/master/Library/Formula/sshpass.rb > sshpass.rb && brew install sshpass.rb`
SUBSCRIPTION_ID=YOUR_SUBSCRIPTION_ID
LOCATION=westeurope
ADMIN_USERNAME=demo
ADMIN_PASSWORD=YOUR_PASSWORD
SA_NAME=YOUR_EXISTING_SA_NAME
SA_CONTAINER_NAME=YOUR_EXISTING_SA_CONTAINER_NAME
# Variabels - Computed
SUFFIX=$(openssl rand -base64 5 | tr -d '/+' | tr '[:upper:]' '[:lower:]' | tr -cd '[:alnum:]' | head -c 5)
RG_NAME="demo-$SUFFIX"
VM_NAME="demo-$SUFFIX"
VM_SA_NAME="sademo$SUFFIX"
VM_DISK_NAME="disk-$SUFFIX"
# Check prerequisites
if [[ $(uname -s) == "Darwin" && $(which sshpass) ]]; then
echo "Install all prerequisites first"
echo "curl -L https://raw.githubusercontent.com/kadwanev/bigboybrew/master/Library/Formula/sshpass.rb > sshpass.rb && brew install sshpass.rb"
exit
fi
# =============================================
# Create Resource group
# =============================================
az group create --name $RG_NAME --location $LOCATION
# =============================================
# Create a VM with azcopy installed
# =============================================
az vm create \
--resource-group $RG_NAME \
--name $VM_NAME \
--image "UbuntuLTS" \
--os-disk-size-gb 1024 \
--admin-username $ADMIN_USERNAME \
--admin-password $ADMIN_PASSWORD \
--generate-ssh-keys \
--output table
VM_IP=$(
az vm show \
--resource-group $RG_NAME \
--name $VM_NAME \
--show-details \
--query publicIps \
--output tsv
)
# Install azcopy on it
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"apt install -y wget && wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1"
# =============================================
# Download the model
# =============================================
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"wget -O llama_download.sh https://raw.githubusercontent.com/shawwn/llama-dl/main/llama.sh; sudo chmod +x llama_download.sh; ./llama_download.sh"
# =============================================
# Upload the model to Azure Storage
# =============================================
# Create a SAS URL for the container so we can upload/download files
# expiry time = 4 hours from now
AZ_SAS_TOKEN_EXPIRY=$(date -v+4H -u +%Y-%m-%dT%H:%MZ)
AZ_SAS_TOKEN=$(az storage container generate-sas --account-name $SA_NAME --name $SA_CONTAINER_NAME --permissions rw --expiry $AZ_SAS_TOKEN_EXPIRY --output tsv)
# Upload the files in the directories 7B, 13B to azure storage under the folder LLaMA
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"sudo azcopy copy '/home/$ADMIN_USERNAME/llama_download.sh' 'https://$SA_NAME.blob.core.windows.net/$SA_CONTAINER_NAME/LLaMA/download.sh?${AZ_SAS_TOKEN}'"
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"sudo azcopy copy '/home/$ADMIN_USERNAME/llama/7B' 'https://$SA_NAME.blob.core.windows.net/$SA_CONTAINER_NAME/LLaMA/7B?${AZ_SAS_TOKEN}' --recursive=true"
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"sudo azcopy copy '/home/$ADMIN_USERNAME/llama/13B' 'https://$SA_NAME.blob.core.windows.net/$SA_CONTAINER_NAME/LLaMA/13B?${AZ_SAS_TOKEN}' --recursive=true"
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"sudo azcopy copy '/home/$ADMIN_USERNAME/llama/30B' 'https://$SA_NAME.blob.core.windows.net/$SA_CONTAINER_NAME/LLaMA/30B?${AZ_SAS_TOKEN}' --recursive=true"
sshpass -p $ADMIN_PASSWORD ssh -t $ADMIN_USERNAME@$VM_IP \
"sudo azcopy copy '/home/$ADMIN_USERNAME/llama/65B' 'https://$SA_NAME.blob.core.windows.net/$SA_CONTAINER_NAME/LLaMA/65B?${AZ_SAS_TOKEN}' --recursive=true"
# =============================================
# Clean up
# =============================================
az group delete --name $RG_NAME --yes --no-waitThis takes around 1.5hours for the entire model download
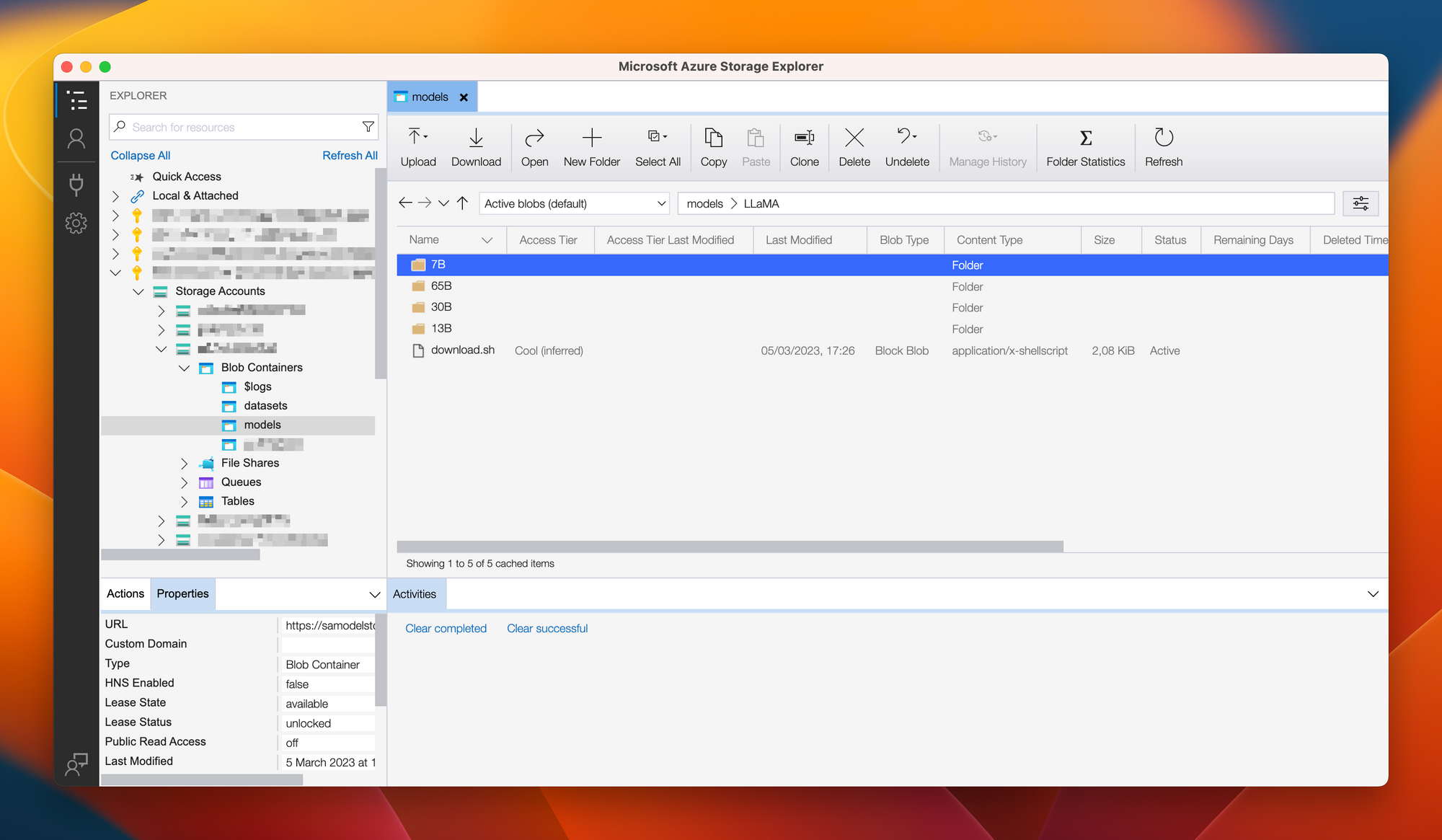
The above will then download all the files and reupload them to Azure. When checking our result with the Azure Storage Explorer, we can see something like the below. Containing ~100GB of model files!
Next up is to figure out how to run the models! Facebook has open source documentation available, but it already shows that it requires 14G for the 7B model and2 * 2 * n_layers * max_batch_size * max_seq_len * n_heads * head_dim bytes as the decoding cache.
| Model | Size | Decoding Cache | Total | Formula |
|---|---|---|---|---|
| 7B | 14GB | 17GB | 31GB | 2 * 2 * 32 * 32 * 1024 * 32 * 128 |
| 13B | 26GB | 25GB | 51GB | 2 * 2 * 40 * 32 * 1024 * 40 * 160 |
| 30B | 64GB | 80GB | 144GB | 2 * 2 * 60 * 32 * 1024 * 52 * 208 |
| 65B | 128GB | 160GB | 288GB | 2 * 2 * 80 * 32 * 1024 * 64 * 256 |
So we can see that the largest model requires ~288GB memory!
Conclusion
As you can see, getting the model downloaded and uploaded to your own store is not too difficult. Running the model for inferencing results however is a different story! This we will explore in another post.


Comments ()