
Analyzing ML/RL Model Performance with Azure Synapse Analytics Spark Pools

I have been following Azure Synapse Analytics since it was still in development and the mock-ups were not finished yet. The vision that Azure Synapse Analytics brings is simply amazing, bringing an End-to-End analytics platform that seamlessly mixes SQL Dedicated, SQL On-Demand, and Spark to prepare, analyze and publish your data needs.
Introduction
For a new project I am working on, I wanted to analyze the performance of my ML Models, but had some trouble finding the right documentation to read analyze my Azure Data Lake storage accounts. Therefore, I wanted to share this through a new blog article.
Please note that this article goes on how we can utilize Azure Synapse to analyze this data and does not goes into how we can create the RL trained models 😊
Prerequisites
Generated Data from Random Agent and Trained Agent
To get started, I generated trajectory sequences for my Reinforcement Learning use case. These sequences are JSON files containing lines with (s, a, r, s', ...) tuples, represented as SampleBatch objects in RLLib
⚠ I dumped this data into an Azure Data Lake Store! You will need the storage account key, storage account container name, and storage account URL later
I created those for 2 agents:
- Random Agent: Agent that takes random actions
- Trained Agent: Agent trained with PPO
As an example, the data would be represented as follows in several chunked JSON files:
{"type": "SampleBatch", "t": [0], "eps_id": [0], "agent_index": [0], "obs": "BCJNGGhAkAAAAAAAAAB5iwAAAFKABZWFAAEA8hmMEm51bXB5LmNvcmUubnVtZXJpY5SMC19mcm9tYnVmZmVylJOUKJYQLgDxBQAGw0I97xhFvG7DerymTD07lIwFQADxFpSMBWR0eXBllJOUjAJmNJSJiIeUUpQoSwOMATyUTk5OSv////8FAPAFSwB0lGJLAUsEhpSMAUOUdJRSlC4AAAAA", "actions": [1], "action_prob": [1.0], "action_logp": [0.0], "rewards": [1.0], "prev_actions": [0], "prev_rewards": [0], "dones": [false], "infos": [{}], "new_obs": "BCJNGGhAkAAAAAAAAAB5iwAAAFKABZWFAAEA8hmMEm51bXB5LmNvcmUubnVtZXJpY5SMC19mcm9tYnVmZmVylJOUKJYQLgDxBQC9xkE9JbU7PiHReby005a+lIwFQADxFpSMBWR0eXBllJOUjAJmNJSJiIeUUpQoSwOMATyUTk5OSv////8FAPAFSwB0lGJLAUsEhpSMAUOUdJRSlC4AAAAA", "unroll_id": [0]}
{"type": "SampleBatch", "t": [1], "eps_id": [0], "agent_index": [0], "obs": "BCJNGGhAkAAAAAAAAAB5iwAAAFKABZWFAAEA8hmMEm51bXB5LmNvcmUubnVtZXJpY5SMC19mcm9tYnVmZmVylJOUKJYQLgDxBQC9xkE9JbU7PiHReby005a+lIwFQADxFpSMBWR0eXBllJOUjAJmNJSJiIeUUpQoSwOMATyUTk5OSv////8FAPAFSwB0lGJLAUsEhpSMAUOUdJRSlC4AAAAA", "actions": [1], "action_prob": [1.0], "action_logp": [0.0], "rewards": [1.0], "prev_actions": [1], "prev_rewards": [1.0], "dones": [false], "infos": [{}], "new_obs": "BCJNGGhAkAAAAAAAAAB5iwAAAFKABZWFAAEA8hmMEm51bXB5LmNvcmUubnVtZXJpY5SMC19mcm9tYnVmZmVylJOUKJYQLgDxBQD+ylA9pt3BPk8srbyzjxe/lIwFQADxFpSMBWR0eXBllJOUjAJmNJSJiIeUUpQoSwOMATyUTk5OSv////8FAPAFSwB0lGJLAUsEhpSMAUOUdJRSlC4AAAAA", "unroll_id": [1]}
...
Azure Synapse Analytics Workspace
Create an Azure Synapse Analytics workspace as explained on the Documentation website
Spark Pool
Once an Azure Synapse Analytics workspace is created, add a Spark Pool to it (see screenshots below).
Gathering our Insights
Creating a notebook
Now we are ready to do the heavy lifting! So open your Synapse Studio and create a new Notebook.
Executing our code
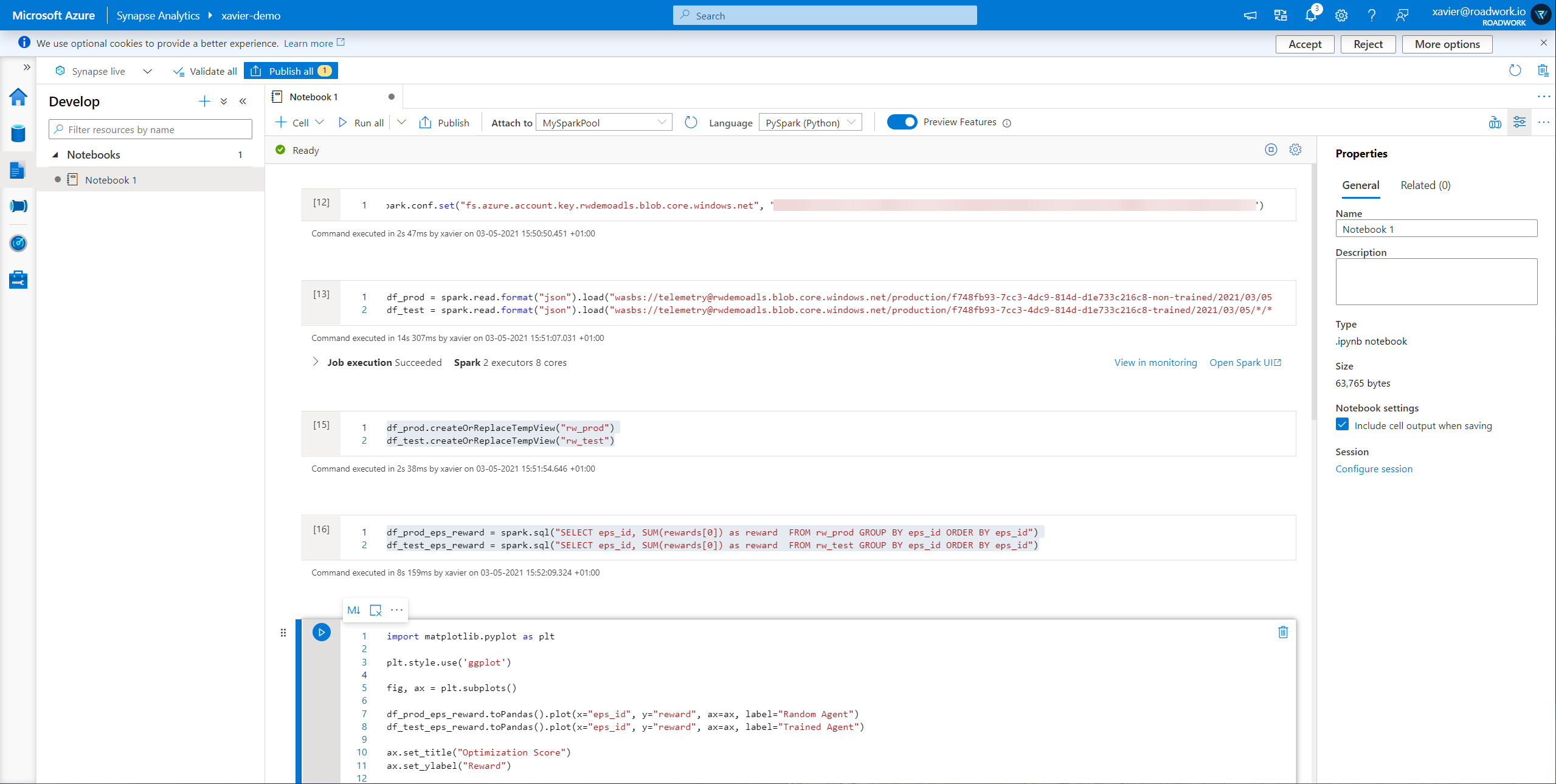
In this notebook, we will create some cells that will connect to the storage account. To connect to a storage account we can utilize the following snippet:
spark.conf.set("fs.azure.account.key.rwdemoadls.blob.core.windows.net", "<YOUR_STORAGE_ACCOUNT_KEY>")
After which we load our datasets into their respective data frames:
df_prod = spark.read.format("json").load("wasbs://[email protected]/production/f748fb93-7cc3-4dc9-814d-d1e733c216c8-non-trained/2021/03/05/12/30/*.json")
df_test = spark.read.format("json").load("wasbs://[email protected]/production/f748fb93-7cc3-4dc9-814d-d1e733c216c8-non-trained/2021/03/05/12/30/*.json")
To make it easier to consume this data, I register it as a table so I can query it:
df_prod.createOrReplaceTempView("rw_prod")
df_test.createOrReplaceTempView("rw_test")
This way, I can run the following query to create new dataframes containing my new data
df_prod_eps_reward = spark.sql("SELECT eps_id, SUM(rewards[0]) as reward FROM rw_prod GROUP BY eps_id ORDER BY eps_id")
df_test_eps_reward = spark.sql("SELECT eps_id, SUM(rewards[0]) as reward FROM rw_test GROUP BY eps_id ORDER BY eps_id")
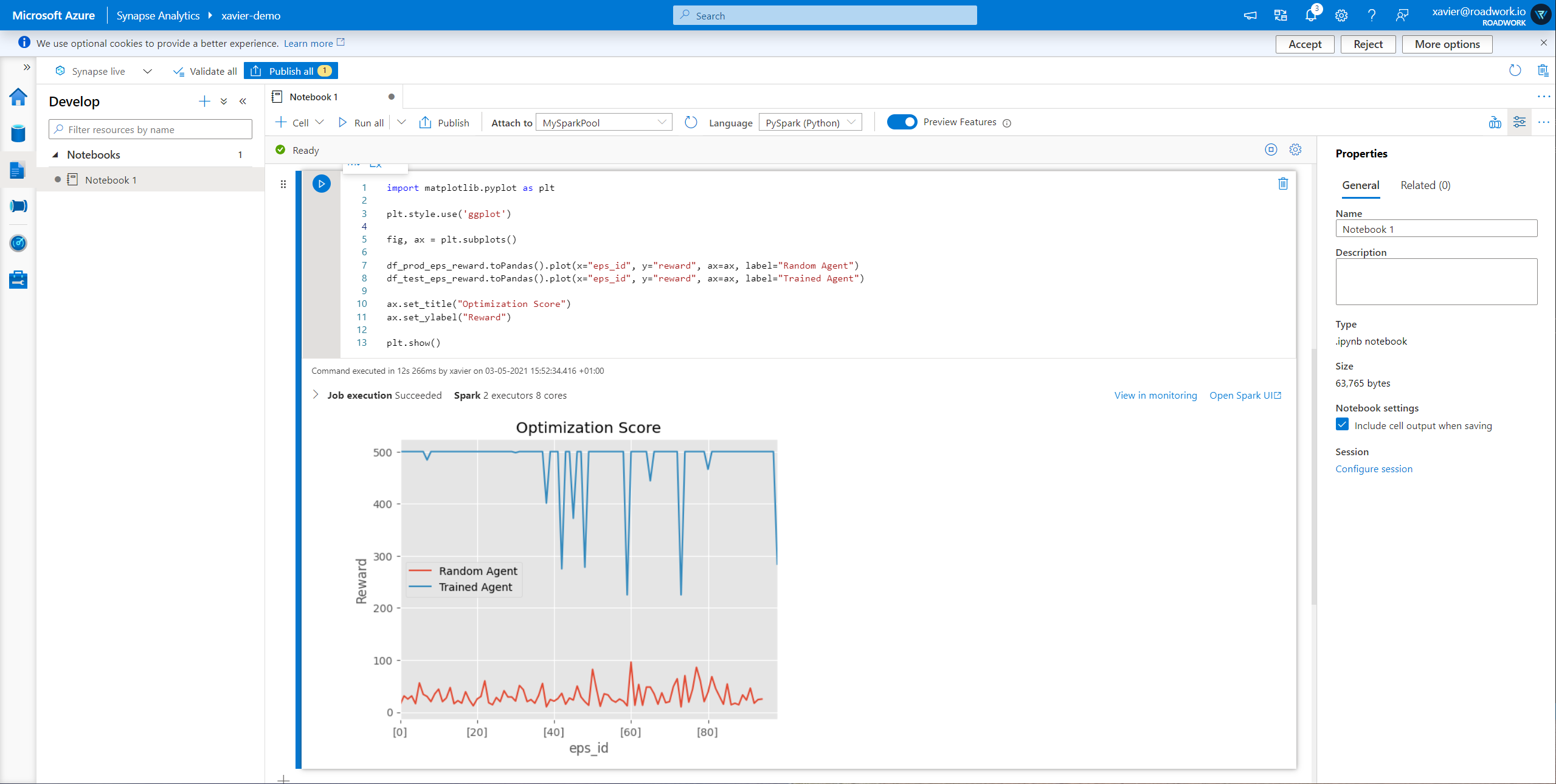
That I can visualize through matplotlib
import matplotlib.pyplot as plt
plt.style.use('ggplot')
fig, ax = plt.subplots()
df_prod_eps_reward.toPandas().plot(x="eps_id", y="reward", ax=ax, label="Random Agent")
df_test_eps_reward.toPandas().plot(x="eps_id", y="reward", ax=ax, label="Trained Agent")
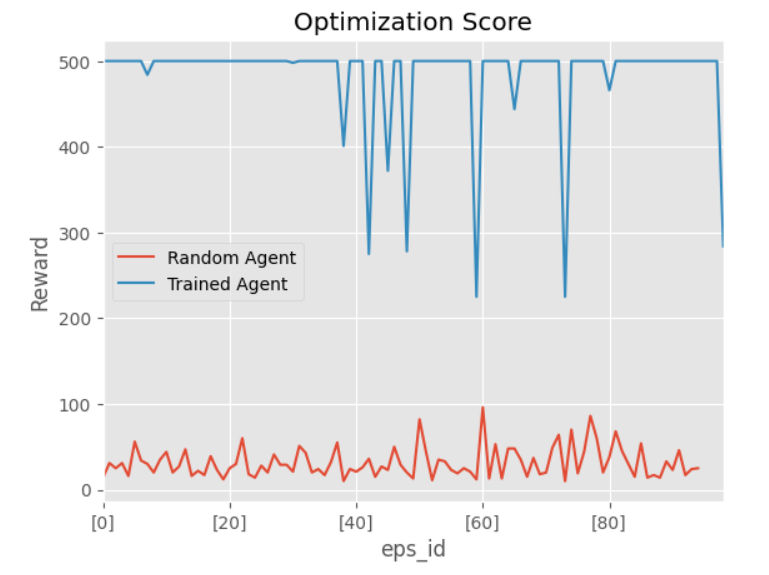
ax.set_title("Optimization Score")
ax.set_ylabel("Reward")
plt.show()
Finally showing
For the full screenshots, see below
Executing our code - Screenshots
Conclusion & Feedback on Azure Synapse
In this article, I went through how you can easily utilize Azure Synapse Spark Pools to analyze your data.
Personally, I am very impressed with the value Azure Synapse can bring for analyzing your data. Having an on-demand cluster that runs while you are utilizing it and provides an end-to-end integrated experience is exactly what I needed for most of my data use cases.
Next to that, my general feedback for the Azure Synapse team would be:
- Notebook UI is amazing, crystal clear, and amazing views for task outputs
- Notebook UI could use some tweaking to not always show "Clear Cell" or "Convert to Markdown", it sits in the way sometimes
- Notebook UI could benefit from "snippets" to connect to storage accounts (I did remember seeing this in mockups, so I am not sure if I missed it though)
- The initial getting started with it is quite difficult, coming from Databricks, I had to figure out which spark code to utilize and it was quite hard to find documentation for my use case (though I might have used wrong keywords)
- I had to use Spark Pools since JSON was not supported in SQL On-Demand which I found sad
Finally, I recommend anyone that is working with data to give Azure Synapse a try! You might get surprised by how powerful it is!


Comments ()