
Implementing Deepmind's MuZero Algorithm with Python
Deepmind has achieved a huge milestone by publishing its latest paper around Reinforcement Learning in Nature - 23/DEC/2020. How they were able to train a Reinforcement Learning algorithm that masters Go, Chess, Shogi and Atari without needing to be told the rules.
Introduction
I have always been interested in Artificial Intelligence. However, when looking at the landscape today, we see that it mainly consists of plain statistics, where we feed an algorithm a lot of data and we will eventually "generalize" well enough, such that it can be utilized on previously unknown datasets. While this has a huge impact on society and a lot of business value is extracted from it, my personal interest is more in the domain of Artificial General Intelligence (AGI) where a machine has the ability to learn an intellectual task without the intervention of a human. Or in a more simple sentence:
🤖 "We throw a task to the machine and it will figure out what to do and become good at it"
Knowledge in Reinforcement Learning
In the figure below - created by Deepmind - we can see that a huge step was taken. Previously we were always required to have a certain knowledge around the domain (Human Data, Domain Knowledge or the Rules of the environment) such as in the AlphaGo engine which then evolved to only requiring to know the rules of the environment (AlphaGo Zero and AlphaZero) but we were never able to remove this requirement. With MuZero we are now able to learn the rules of the games, removing the need for knowledge

With this article, I mainly want to focus on applying the MuZero algorithm myself for the Lunar Lander environment.
For more information around what MuZero exactly introduces and an in-depth coverage of it, I would recommend to check out the following resources:
MuZero Architecture
As detailed in the MuZero Code overview, we can find the pseudocode in pseuducode.py in the supplementary information.
The Pseudocode has the def muzero() that will start the algorithm for us. This will in its turn run 2 independent parts:
- Network Training
- Self Play data generation
def muzero(config: MuZeroConfig):
storage = SharedStorage()
replay_buffer = ReplayBuffer(config)
for _ in range(config.num_actors):
launch_job(run_selfplay, config, storage, replay_buffer)
train_network(config, storage, replay_buffer)
return storage.latest_network()
The Pseudocode above will thus create actors that will take a snapshot of the latest network and make it available to the training job by writing it to a shared replay buffer.
To visualize this I created a simple diagram:
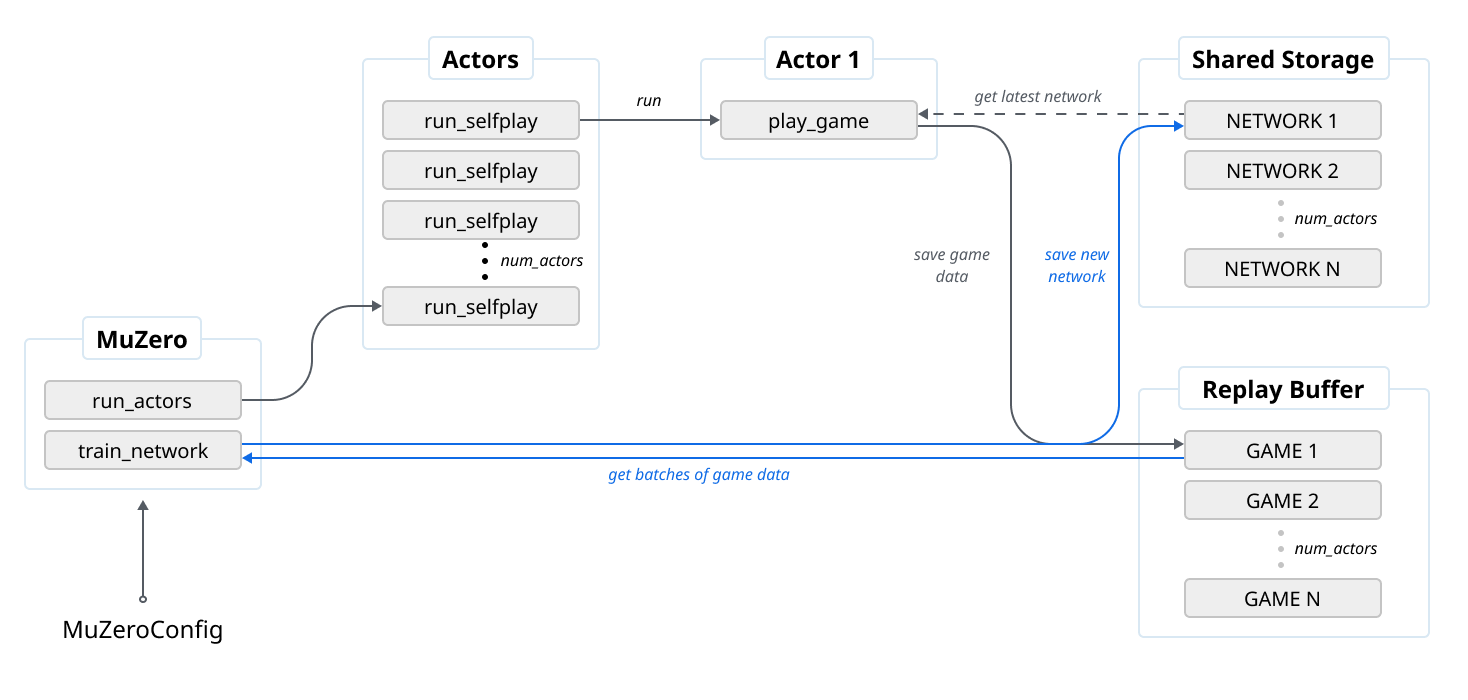
MuZero Running
Now let's get started on running the MuZero algorithm ourselves!
For my system I am using the following configuration:
- Operating System: Windows (Running WSL Ubuntu 20.04)
- Python: 3.8.6 64-bit
❗ I would recommend following my previous article that goes into more detail on how you can setup WSL with NVIDIA
Once all of this is working (which might take a while), we can start setting up our project. In this article, I have chosen to utilize the excellent repository written by Werner Duvaud, seeing that he already implemented the algorithm on specific environments.
To run it yourself, feel free to utilize these commands:
# Clone repository
git clone https://github.com/werner-duvaud/muzero-general.git
# Open repository
cd muzero-general/
# Install PyTorch
# Note: you might need to customize this for your environment
# https://pytorch.org/get-started/locally/
python -m pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
# Install dependencies for the Gym Environment
sudo apt install cmake zlib1g-dev xorg-dev libgtk2.0-0 swig python-opengl xvfb
# Install Atari for the Gym Environment
python -m pip install gym[atari]
After the above has been executed, you should now be able to run the repository code through the commands below to start the training process.
python muzero.py
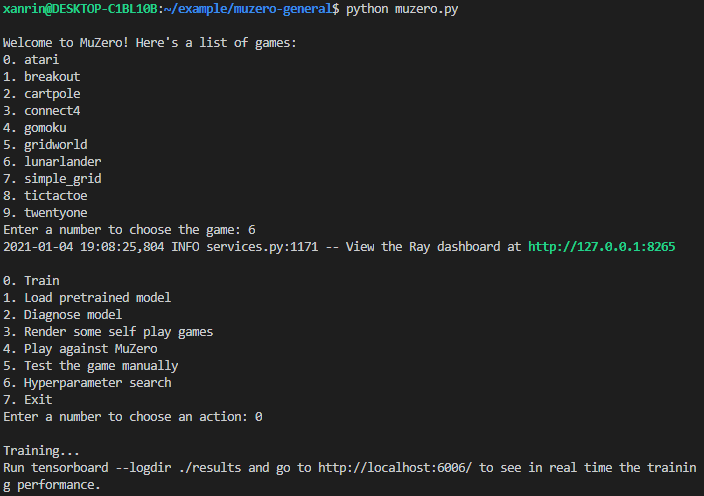
To view the training we can run Tensorboard within our windows environment with tensorboard --logdir ./results --bind_all which will show us our results:

After training finishes, we can use the created model, resulting in the results below.
Note: you can export the display with export DISPLAY=$(ip route | awk '/^default/{print $3; exit}'):0 in WSL
Conclusion
Congratulations! We have just applied the MuZero algorithm and were able to train the Lunar Lander environment correctly 😎 of course this is not a representation of the real world, so you should definitely test this yourself! But it's a start!
Seeing the interesting architecture of MuZero and the utilization of Actors, my next idea would be to try to utilize Dapr to start the out-scaling process. Hopefully I will be able to adopt some of the practices here and apply them in my recently released Roadwork-RL library.
Let me know what you think!


Comments ()