
Reinforcement Learning with the Bonsai Platform

The Bonsai Machine Teaching platform has been released! Promising an easy to use environment for end-to-end Reinforcement Learning projects, starting with simulator selection / integration to algorithm configuration and training.
Of course I had to instantly try this out! Seeing that I "stalked" this team endlessly for over a year 😉
Let's try using the platform for our simple "CartPole" example as covered before..
Understanding Brains and Inkling
Introduction
Bonsai utilizes the concept called "Brains". This concept is quite similar to my previously detailed digital twin and reinforcement learning combination posts, where they create an Inkling program that goes over the State, Action and Reward definitions.
Next to these definitions, there is also meta information added such as the configuration of the environment, which simulation environment to utilize, when the terminal state is reached, …
At the end of this file, a block is added that summarizes all of this together, called a concept with curriculum.
Creating a Brain for CartPole
When we dive into the example for the "Stellar Cartpole" problem, we can find a beautiful example worked out for us that can train the cartpole environment.
To go a bit more in detail, let's break this up in the respective State, Action and Reward definition as well as Concept creation.
State (state received from simulator):
# Full Simulator State
type SimState {
cart_position: number,
cart_velocity: number,
pole_angle: number,
pole_angular_velocity: number
}
Action (actions to take):
type SimAction {
command: number<-1 .. 1> # Left = -1, None = 0, Right = 1
}
Reward:
In Cartpole we want it to stay stable. Stable can be defined in multiple ways, but to give 2 examples:
- Getting the Cartpole as stable as possible (e.g. go for the longest number of iterations, taking the rotation angle into account as a negative reward)
- Making the Cartpole survive (e.g. go for the longest number of iterations - shown below)
function BalancePoleReward(State: SimState) {
# Reward it for not falling.
return 1.0
}
Concept / Curriculum:
# Define a concept graph with a single concept
graph (input: SimState): SimAction {
concept BalancePole(input): SimAction {
curriculum {
# The source of training for this concept is a simulator
# that takes an action as an input and outputs a state.
source simulator (Action: SimAction): SimState {
# Automatically launch the simulator with this
# registered package name.
package "Cartpole"
}
# The objective of training is expressed as a goal with two
# subgoals: don't let the pole fall over, and don't move
# the cart off the track.
goal (State: SimState) {
avoid `Fall Over`:
Math.Abs(State.pole_angle) in Goal.RangeAbove(MaxPoleAngle)
avoid `Out Of Range`:
Math.Abs(State.cart_position) in Goal.RangeAbove(TrackLength / 2)
}
training {
# Limit the number of iterations per episode to 120. The default
# is 1000, which makes it much tougher to succeed.
EpisodeIterationLimit: 120
}
}
}
}
All of this is thrown into an easy to use interface:
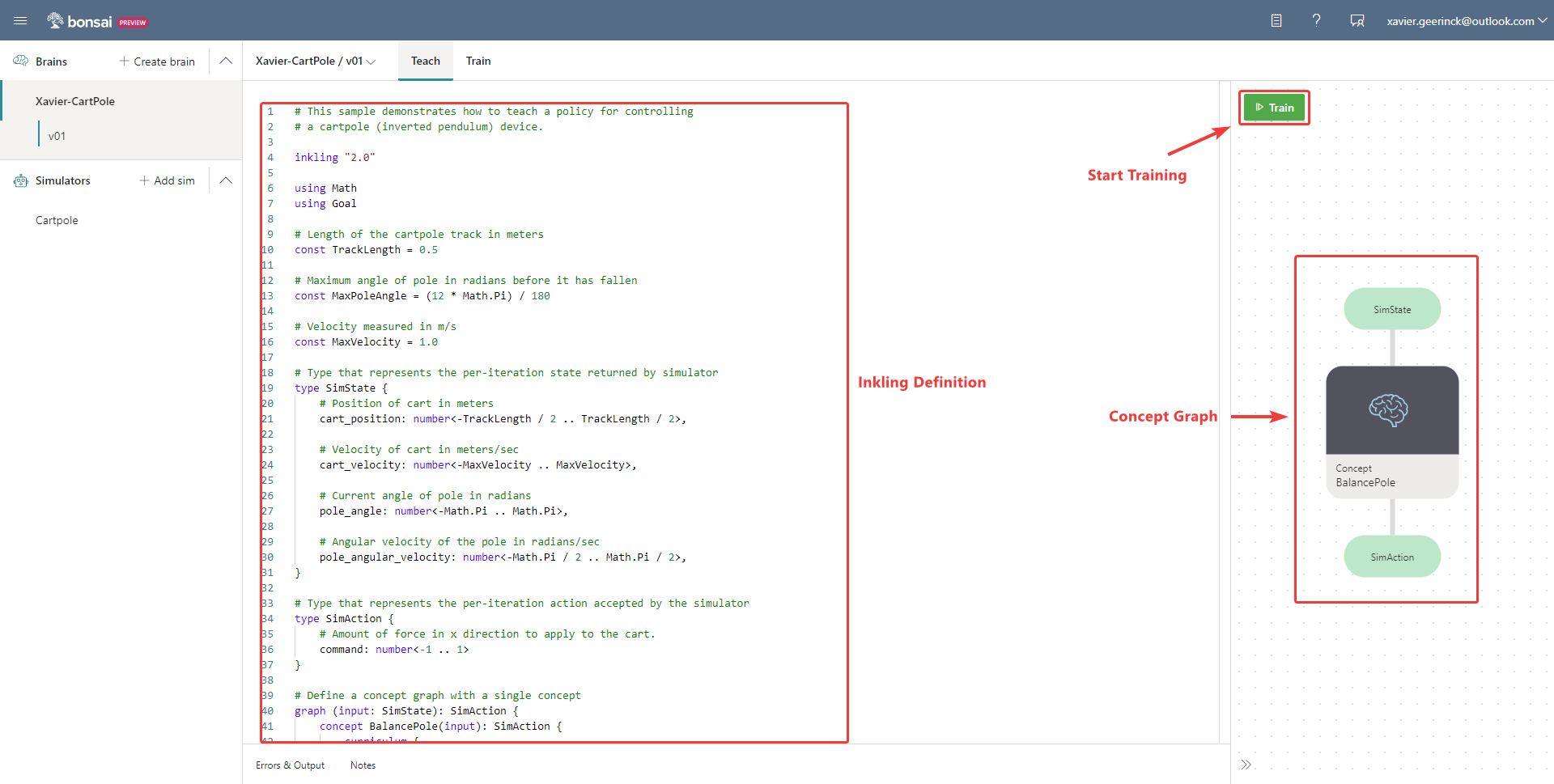
Training our Brain
Once the Brain has defined, it's as easy as clicking the "Start Training" button as displayed above. This will kick of the learning platform that will automatically spin up the underlying training environment cluster and simulator to start maximizing our reward. There is no need to know anything about Reinforcement Learning algorithms to actually train the model! 😉
What I love here is how clear they made it that the simulator is our "World" and that the agent is taking actions and receiving observations.

After a couple of minutes of training we are starting to see the reward increase beautifully, reaching the same reward as our previous Cartpole Example description which utilizes Q-Learning algorithm after ~1hr.
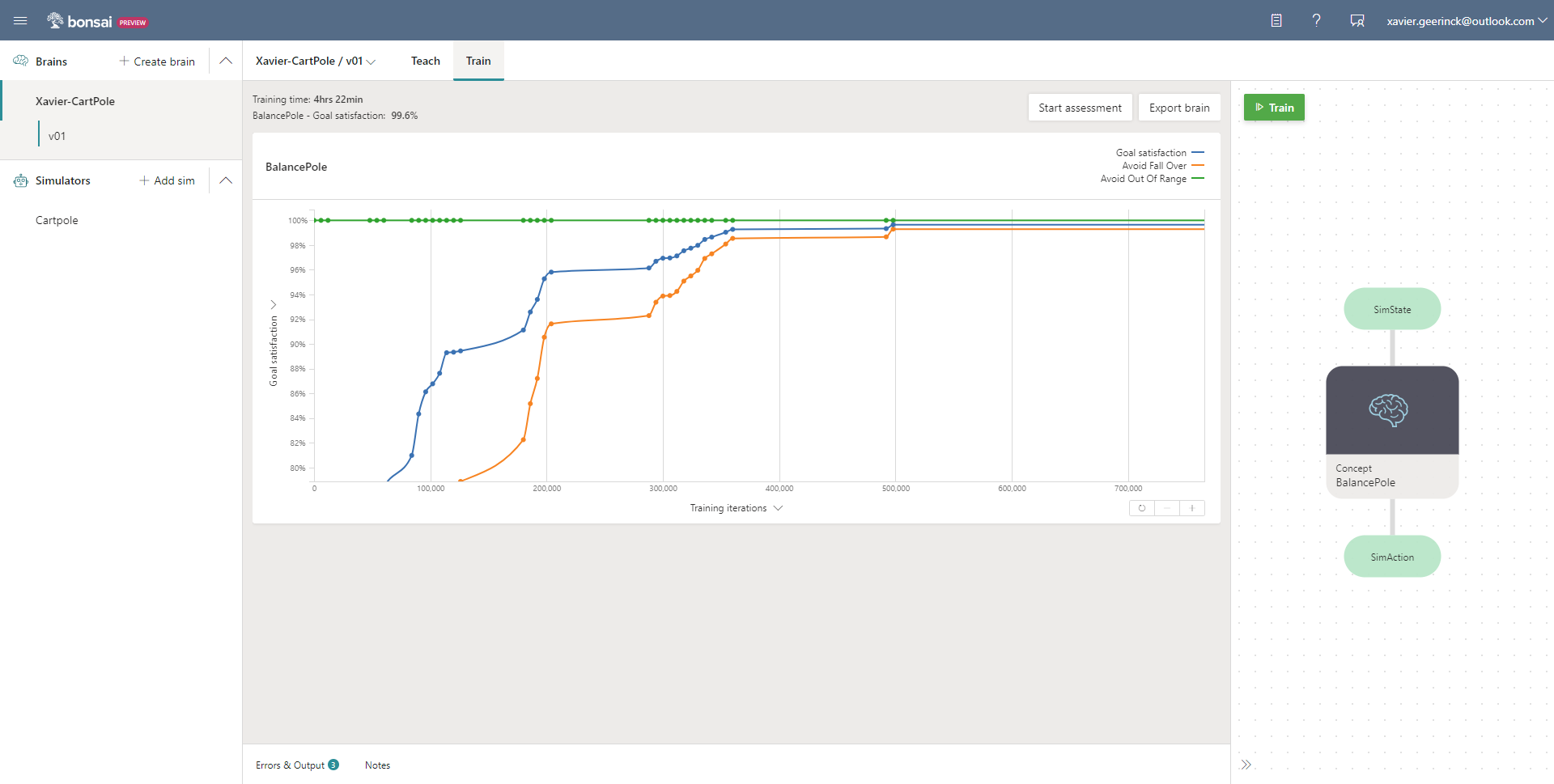
A thing I noticed is that training seems to go slower compared to testing it on myself. This is due to the usage of Deep Reinforcement Learning! The state action discritization is using a Neural Net rather than a fixed state array, thus on these small environments taking a longer time. When we would run this on a large-world example with millions of states, we would mainly look at a Neural Network.
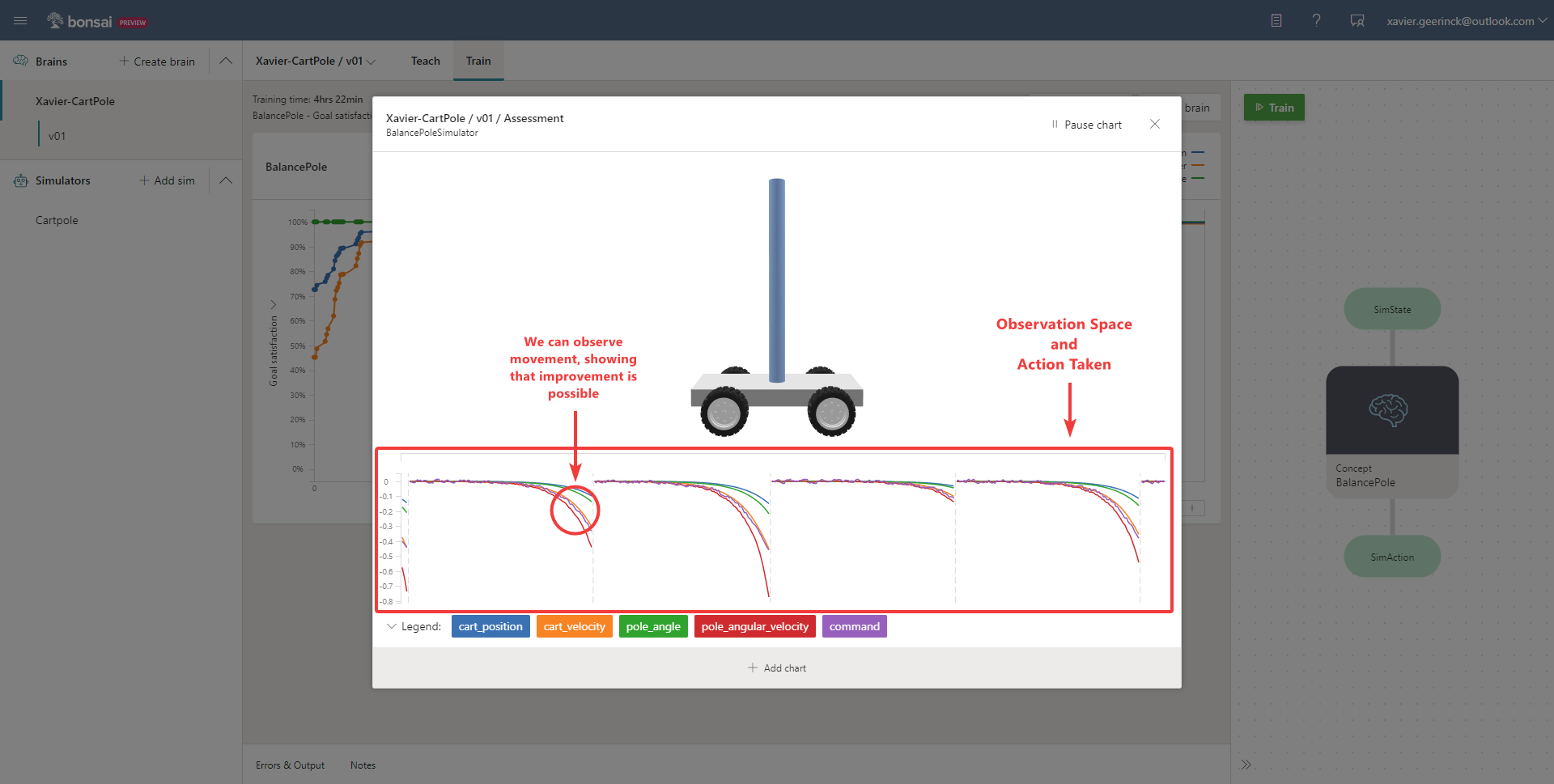
Testing the Brain
Once the Brain is trained, we can start an assessment that will launch the CartPole environment and visualize it, showing how well our brain is performing.
What I love here is that we are able to see different charts, illustrating what is happening in the observation space.
Conclusion
All of the above might look easy, but this is because the Bonsai platform makes it easy! It's no easy feat towards such a beautiful simulation integration as well as automated (and abstracted away) training.
Therefor, a big well done to the entire Bonsai team for making this such an amazing platform, I can't wait to see how it will evolve over the coming years.


Comments ()