
Abusing the Bing Search API to get access to Data and Visualize it

Introduction
These days it's all about the privacy of users, API access to all platforms is being limited and locked down, so that developers are not able to abuse this anymore.
This of course works well, but there is still one thing I think they overlooked: Crawlers! Just think about it, what is an API? An API stands for "Application Programming Interface" and allows a program to easily communicate with the data that it has based on an interface. But what does a Crawler do? Well the definition of a crawler is: "Web search engines and some other sites use Web crawling or spidering software to update their web content or indices of others sites' web content. Web crawlers copy pages for processing by a search engine which indexes the downloaded pages so users can search more efficiently.". Did you notice the part in bold? We can also refer to this as putting a layer on top of our data to make it easy to search through it - sounds closely related to an API right?
But how can we efficiently do this? Since writing a Crawler would take a long time (and not to mention the compute power required for it) - I actually wrote one, believe me it's not something you want to do. How about using something of the "Big Players"?
Doing some research about the ones popping up in my head instantly returned these results:
- Google (5$ per 1.000 queries, limited to 10.000 queries per day) --> This is too much and also would limit us
- Microsoft Bing (3$ per 1.000 transactions on the S2 tier but I did NOT find any limit) --> I think we found our API
In case you only care about the business part and not the coding, this is the end result that we will be creating by the end of this post :)
Building a use case and creating our Bing API Interface
Let's build a Use Case for this to create a demo script. What about writing a tool that effectively is able to get LinkedIn users for a given company to make our lives easier to identify key people within an organization? This sounds like something a company would use right?
Note: Actually this is what is called "Sales Navigator" on LinkedIn, but by building this API we could enrich it with Twitter and other data to make it more intelligent ;)
Quickly writing up a script that consumes the Bing Search API gives us:
const fetch = require('node-fetch');
// Based on https://github.com/Microsoft/BotFramework-Samples/blob/master/StackOverflow-Bot/StackBot/lib/bingsearchclient.js
class BingSearchClient {
constructor(key) {
if (!key) throw new Error('bingSearchKey is required');
this.bingSearchKey = key;
this.bingSearchCount = 50;
this.bingSearchMkt = "en-us";
this.bingSearchBaseUrl = "https://api.cognitive.microsoft.com/bing/v7.0/search";
this.bingSearchMaxSearchStringSize = 150;
}
get(search, offset = 0, cb) {
return new Promise((resolve, reject) => {
if (!search) throw new Error('Search text is required');
cb = cb || (() => {});
const searchText = search.substring(0, this.bingSearchMaxSearchStringSize).trim();
const url = this.bingSearchBaseUrl + "?"
+ `q=${encodeURIComponent(searchText)}`
+ `&count=${this.bingSearchCount}`
//+ `&mkt=${this.bingSearchMkt}`
+ `&offset=${offset}&responseFilter=Webpages&safesearch=Strict`;
try {
fetch(url, {
method: 'GET',
headers: {
"Ocp-Apim-Subscription-Key": this.bingSearchKey
}
})
.then((response) => response.json())
.then((json) => resolve(json));
} catch (e) {
return reject(e);
}
})
}
}
module.exports = BingSearchClient;
Building our LinkedIn Discovery Tool
Since we have our API that can interface with the Bing Web Search API, we are now able to run queries on it. One interesting query for our LinkedIn results is:
site:linkedin.com "${companyName} | LinkedIn"
This will go through the Bing Engine and only look at our Linkedin.com website results. By then defining "${companyName} | LinkedIn" we "kind of" restrict it to the results we want.
Applying some regexes on the Titles and Urls to filter out the results, will give us the following details of the users:
- Name
- Username
- Role
- URL
This is nice already right? We got the base data which we can enrich with other sources, so let's build this!
The way I quickly build this together is by using redis as a queue and a cache allowing for a mechanism that can be triggered through a REST call to start the discovery phase (putting it on the queue and processing it) and then updating the redis cache when it is done.
The code that does all of this is:
const HashSetAPI = require('../../../API/HashSet');
const hashSet = new HashSetAPI();
const Queue = require('bull');
const discoverUsersLinkedInQueue = new Queue('discover-users-linkedin', 'redis://127.0.0.1:6379');
const config = require('../../../config');
const BingSearchClient = require('../../../API/BingSearchClient');
const bingSearchClient = new BingSearchClient(config.bingSearch.key);
const LIMIT_DUPLICATE_USERS_PER_PAGE = 30;
const LIMIT_PAGE = 50; // Stop after page
const LIMIT_PAGE_STAGNATED = 5; // If we add 0 people for X pages, stop
/**
* job: { name: <name> }
*/
discoverUsersLinkedInQueue.process(async (job, done) => {
const companyName = job.data.name;
// Get our previous object our init a new blank one
let peopleMap = await hashSet.get(companyName);
peopleMap = peopleMap || {
people: {},
wrongResults: [], // Set of objects containing the wrong results for further analysis
meta: {
isDone: false,
offset: 0,
duplicatesOnPage: 0,
duplicatesTotal: 0,
peopleFoundOnPage: 0,
peopleFoundTotal: 0,
page: 0, // Current page
pageStagnated: 0,
}
} // Default peopleMap
console.log(`[Discoverer] Starting discovery for ${companyName}, peopleFound: ${peopleMap.meta.peopleFoundTotal}, peopleFoundOnPage: ${peopleMap.meta.peopleFoundOnPage}, duplicates: ${peopleMap.meta.duplicatesTotal}, stagnated: ${peopleMap.meta.pageStagnated}`);
// See if any of the limits were reached and if we should stop
let shouldContinue = true;
shouldContinue = !(peopleMap.meta.offset >= LIMIT_PAGE);
shouldContinue = !(peopleMap.meta.duplicatesOnPage >= LIMIT_DUPLICATE_USERS_PER_PAGE);
shouldContinue = !(peopleMap.meta.pageStagnated >= LIMIT_PAGE_STAGNATED);
// @todo: add shouldContinue check for last date checked, this way records expire
if (!shouldContinue) {
console.log(`[Discoverer] Done discovering ${companyName}`);
peopleMap.meta.isDone = true;
await hashSet.set(companyName, peopleMap);
return done();
}
// Download page
const result = await bingSearchClient.get(`site:linkedin.com "${companyName} | LinkedIn"`, peopleMap.meta.offset);
const parsed = await parseLinkedInPage(companyName, result.webPages.value, peopleMap);
// Store results
await hashSet.set(companyName, parsed);
// Put back on queue for further exploration
discoverUsersLinkedInQueue.add({ name: companyName, isExploring: true });
console.log('[Discoverer] Adding result back for more exploration');
done();
});
/**
*
* @param {string} companyName
* @param {array} pages array of objects [ { name, url }, ... ]
* @param {map} peopleMap a map of the current found people, gotten from our store looks like: { people: {}, wrongResults: [], meta: { offset, duplicates } }
* @return {object} { people: {}, meta: { offset, duplicates } }
*/
const parseLinkedInPage = async (companyName, pages, peopleMap) => {
const usernameRegex = new RegExp('linkedin.com\\/in\\/([a-zA-Z0-9\\-]*)', 'i'); // [1] gives username on LinkedIn from the URL
// Filter pages that are as we wanted it (correct information)
// This means we will loop over all results twice
// --> @todo: is this needed?
let filteredResults = [];
pages.forEach((i) => {
// Check URL format
if (!i.url.match(usernameRegex)) {
peopleMap.wrongResults.push({
title: i.name,
url: i.url
});
return;
}
filteredResults.push(i);
});
let duplicates = 0;
let peopleFound = 0;
// Extract people and put them in peopleMap
filteredResults.forEach((i) => {
let { name, role } = extractNameRoleCompanyFromTitle(companyName, i.name);
let { username } = extractUsernameFromUrl(i.url);
// If no username found, show an error
if (!name || !role || !username) {
console.error(`[Discoverer] Undefined parameter found in ${JSON.stringify(i)}
Name: ${name}
Role: ${role}
Username: ${username}
`);
return;
}
// If we already have this result, mark as duplicate, else store it
if (peopleMap.people[username]) {
duplicates++;
} else {
peopleFound++;
peopleMap.people[username] = {
username,
name,
role,
url: i.url
}
}
});
return {
people: peopleMap.people,
wrongResults: peopleMap.wrongResults,
meta: {
duplicatesOnPage: duplicates,
duplicatesTotal: peopleMap.meta.duplicatesTotal + duplicates,
offset: peopleMap.meta.offset + pages.length,
peopleFoundOnPage: peopleFound,
peopleFoundTotal: Object.keys(peopleMap.people).length,
page: peopleMap.meta.page + 1,
pageStagnated: (peopleFound == 0) ? peopleMap.meta.pageStagnated + 1 : 0,
}
};
}
const extractNameRoleCompanyFromTitle = (companyName, webpageTitle) => {
let name;
let title;
let role;
const titleRegex = new RegExp(`^(.*) - (.*) - ${companyName} \\| LinkedIn$`, 'i'); // [1] gives name, [2] gives role
if (titleRegex.test(webpageTitle)) {
let res = titleRegex.exec(webpageTitle);
name = res[1];
role = res[2];
return { name, role };
}
// NOTE: – is a special character!
const titleRegex2 = new RegExp(`^(.*) – (.*) – ${companyName} \\| LinkedIn$`, 'i'); // [1] gives name, [2] gives role
if (titleRegex2.test(webpageTitle)) {
let res = titleRegex2.exec(webpageTitle);
name = res[1];
role = res[2];
return { name, role };
}
// Extracts name and role from results as in:
// Randy Street - Executive Director Product ... - LinkedIn
// Keith Moody - Director, Analytics COE - LinkedIn
const titleRegex3 = new RegExp(`(.*) - (.*) .* - LinkedIn`, 'i'); // [1] gives name, [2] gives role
if (titleRegex3.test(webpageTitle)) {
let res = titleRegex3.exec(webpageTitle);
name = res[1];
role = res[2];
return { name, role };
}
// Extracts name and role from results as in:
// Cameron Ahler - Executive Director, Enterprise ...
// NOTE: This is a very broad matching, which is why the first already pre-return the result
const titleRegex4 = new RegExp(`(.*) - (.*)\\s\\.\\.\\.`, 'i');
if (titleRegex4.test(webpageTitle)) {
let res = titleRegex4.exec(webpageTitle);
name = res[1];
role = res[2];
return { name, role };
}
return {
name,
role
}
}
const extractUsernameFromUrl = (url) => {
const usernameRegex = new RegExp('linkedin.com\\/in\\/([a-zA-Z0-9\\-\\%]*)', 'i'); // [1] gives username on LinkedIn from the URL
let username;
if (usernameRegex.test(url)) {
let res = usernameRegex.exec(url);
username = res[1];
return { username };
}
return {
username
}
};
Creating our API Server
For the API server, I wanted a lightweight API system that allows me to write my API in as few files as possible while still being easy and lean. Therefor after checking some framework, I went for "Koa.js".
This could probably have been written better, but seeing the time put in this, I am quite happy with the result :)
Server.js
const Koa = require('koa');
const indexRoutes = require('./routes/index');
const companyRoutes = require('./routes/company');
const app = new Koa();
const PORT = process.env.PORT || 3001;
app.use(indexRoutes.routes());
app.use(companyRoutes.routes());
const server = app.listen(PORT, () => {
console.log(`[Server] Running on http://127.0.0.1:${PORT}`);
});
routes/company.js
const Router = require('koa-router');
const router = new Router();
const Queue = require('bull');
const discoverUsersLinkedInQueue = new Queue('discover-users-linkedin', 'redis://127.0.0.1:6379');
const Redis = require('../../API/Redis');
const redis = new Redis();
router.get('/company/:company/start', async (ctx) => {
const companyName = ctx.params.company;
discoverUsersLinkedInQueue.add({ name: companyName });
ctx.body = {
company: companyName,
isStarted: true
};
});
router.get('/company/:company/check-status', async (ctx) => {
const companyName = ctx.params.company;
let result = await redis.get(companyName);
if (!result) {
ctx.body = {
isDone: false
}
return;
}
result = JSON.parse(result);
ctx.body = {
isDone: result && result.meta && result.meta.isDone
}
});
router.get('/company/:company', async (ctx) => {
const companyName = ctx.params.company;
let result = await redis.get(companyName);
if (!result) {
ctx.status = 404;
ctx.body = {
message: 'result is undefined, start a new crawling process first'
};
return;
}
result = JSON.parse(result);
if (!result.meta.isDone) {
ctx.status = 404;
ctx.body = {
message: 'crawler is busy'
};
return;
}
ctx.body = result;
});
module.exports = router;
Creating our Frontend
For the frontend then, I went for my all-time favorite: next.js allowing me to quickly write server rendered react.js code.
Putting it in the pages/company.js allowed me to quickly access it on the frontend.
import fetch from 'isomorphic-unfetch';
import { withRouter } from 'next/router';
import React from 'react';
class Index extends React.Component {
constructor(props) {
super(props);
this.state = {
isLoaded: props.isLoaded,
map: props.map
};
}
render() {
if (this.state.isLoaded) {
return this.renderLoaded();
} else {
return this.renderNotLoaded();
}
}
renderLoaded() {
return (
<div>
<h1>{this.props.router.query.company} (found: {JSON.stringify(this.state.map.meta.peopleFoundTotal)})</h1>
<table>
<thead>
<tr>
<td>username</td>
<td>name</td>
<td>role</td>
<td>url</td>
</tr>
</thead>
<tbody>
{Object.keys(this.state.map.people).map(key => {
return (
<tr>
<td>{ key }</td>
<td>{this.state.map.people[key].name}</td>
<td>{this.state.map.people[key].role}</td>
<td><a href={this.state.map.people[key].url}>{this.state.map.people[key].url}</a></td>
</tr>
)
})}
</tbody>
</table>
</div>
)
}
renderNotLoaded() {
// Quick and dirty check for loaded result
const companyName = this.props.router.query.company;
let int = setInterval(async () => {
const res = await fetch(`http://127.0.0.1:3001/company/${companyName}/check-status`);
const data = await res.json();
if (data.isDone) {
clearInterval(int);
const res2 = await fetch(`http://127.0.0.1:3001/company/${companyName}`);
const data2 = await res2.json();
this.setState({
isLoading: false,
map: data2
})
}
}, 2000);
return (<div>Loading... (see network tab)</div>);
}
}
Index.getInitialProps = async function (props) {
const companyName = props.query.company;
const res = await fetch(`http://127.0.0.1:3001/company/${companyName}`);
// If not found, we need to poll, start the process in bg
await fetch(`http://127.0.0.1:3001/company/${companyName}/start`);
if (res.status != 404) {
const data = await res.json();
return {
isLoaded: true,
map: data
}
}
return { map: {}, isLoading: true }
}
export default withRouter(Index);
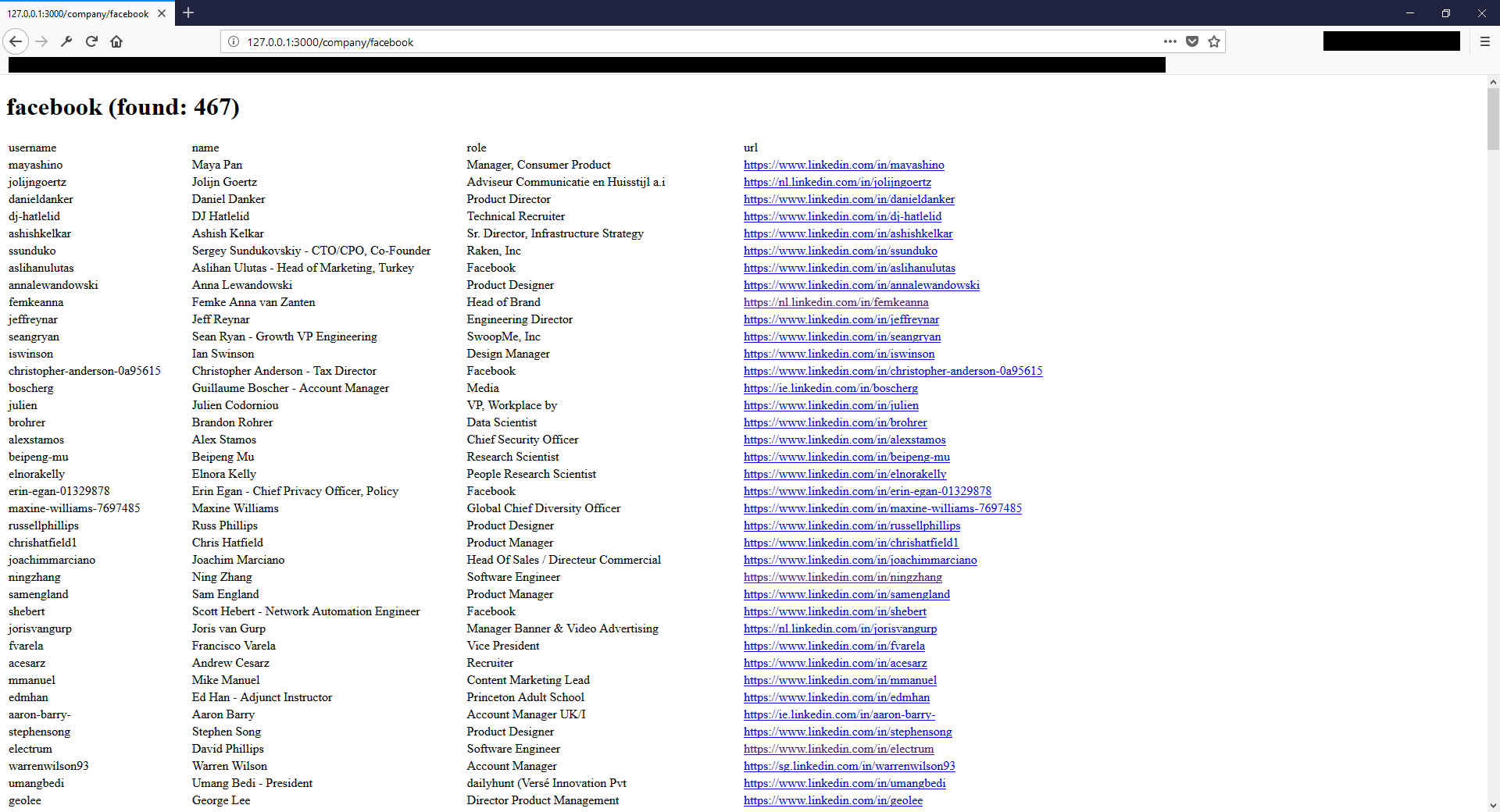
Result
When now going to our created website through http://127.0.0.1:3000/company/facebook we get a list of quickly scraped profiles like this:
Misc
HashSet.js
const redis = require('redis'); // Note: Should become a permanent storage later, now in memory
const redisClient = redis.createClient();
class HashSet {
async get(key) {
return new Promise((resolve, reject) => {
redisClient.get(key, (err, reply) => {
if (err) {
throw err;
}
return resolve(JSON.parse(reply));
});
})
}
async set(key, val) {
return new Promise((resolve, reject) => {
// @TODO: CHECK IF TYPEOF OBJECT
redisClient.set(key, JSON.stringify(val));
return resolve();
});
}
}
module.exports = HashSet;
Redis.js
const redis = require('redis'); // Note: Should become a permanent storage later, now in memory
class Redis {
constructor() {
this.client = redis.createClient();
}
async get(key) {
return new Promise((resolve, reject) => {
this.client.get(key, (err, reply) => {
if (err) {
throw err;
}
return resolve(reply);
});
})
}
}
module.exports = Redis;


Comments ()