
Live Delta Lake with Azure ADF and Databricks DLT
Create a live incrementally loaded delta lake with Azure and Databricks through Azure Data Factory (ADF), Delta Tables and Databricks Delta Live Tables

As touched upon before, incremental loading is the holy grail of data engineering, as it reduces the compute power required, saving time and much needed compute costs. Sadly enough, as we know, this is not an easy feat. Now, luckily for us, this all changes with Azure Data Factory and Databricks Delta Live Tables!
What we are going to be creating is the below, where data moves in towards the Bronze (RAW) from our SQL Server through our Azure Data Factory, towards Silver to curate it and finally Gold where can pick it up for consumption.
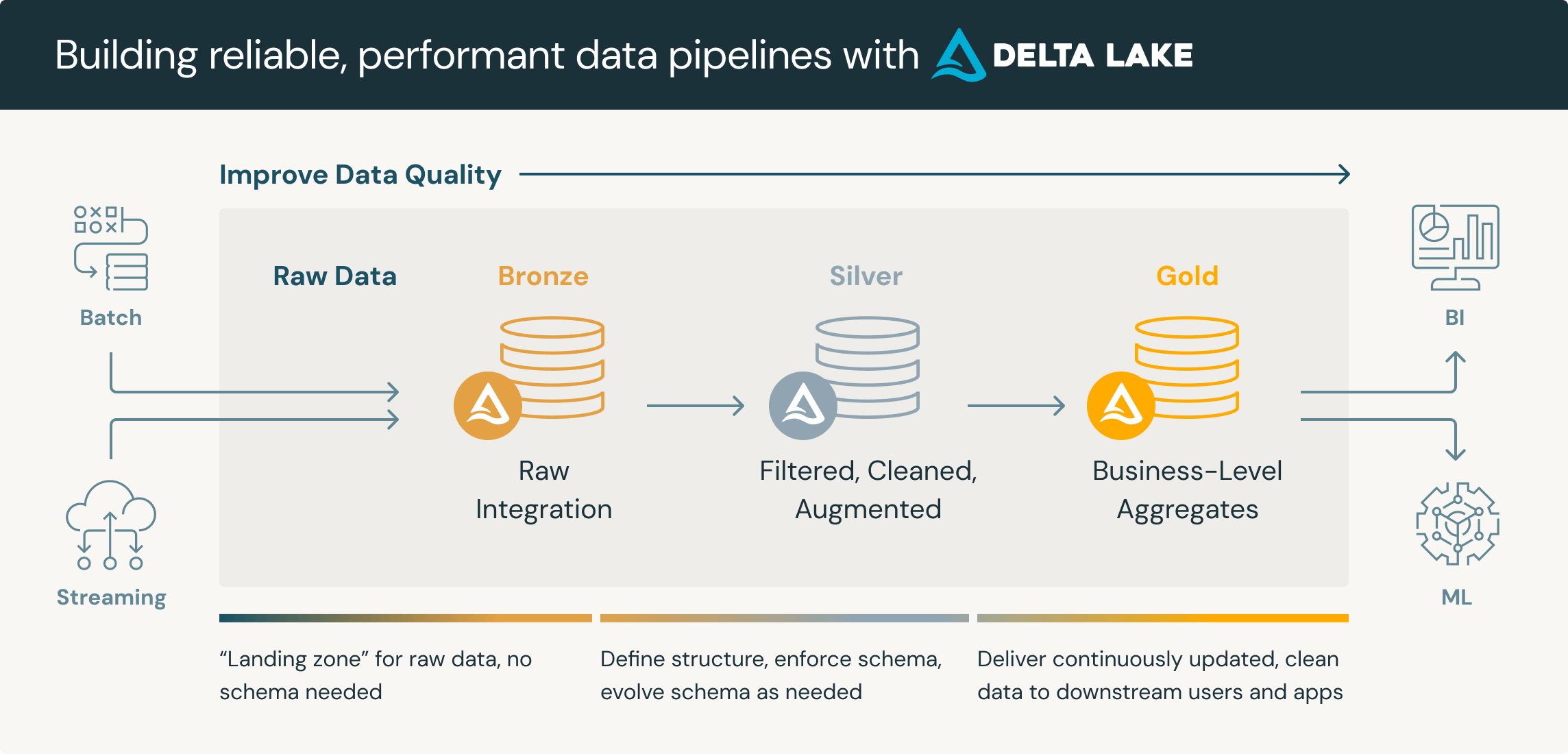
The beauty in this process is that we just process the changes, creating a very efficient process!
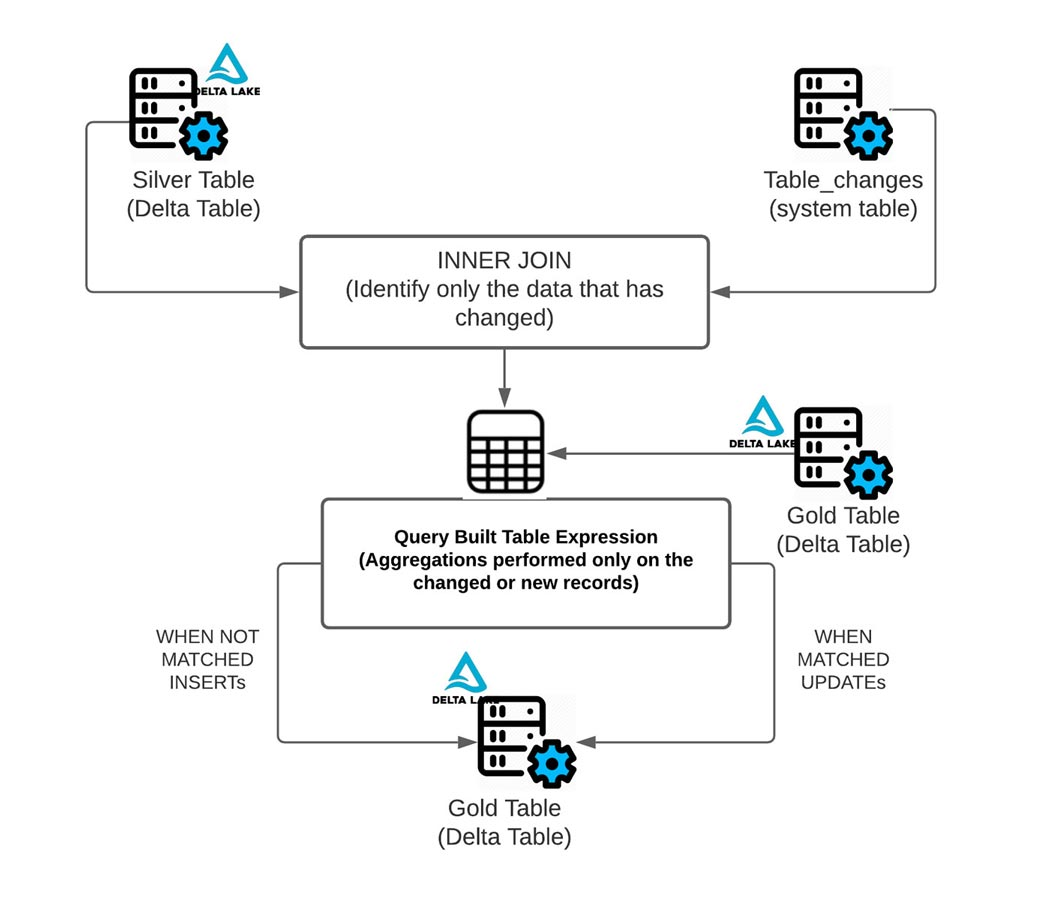
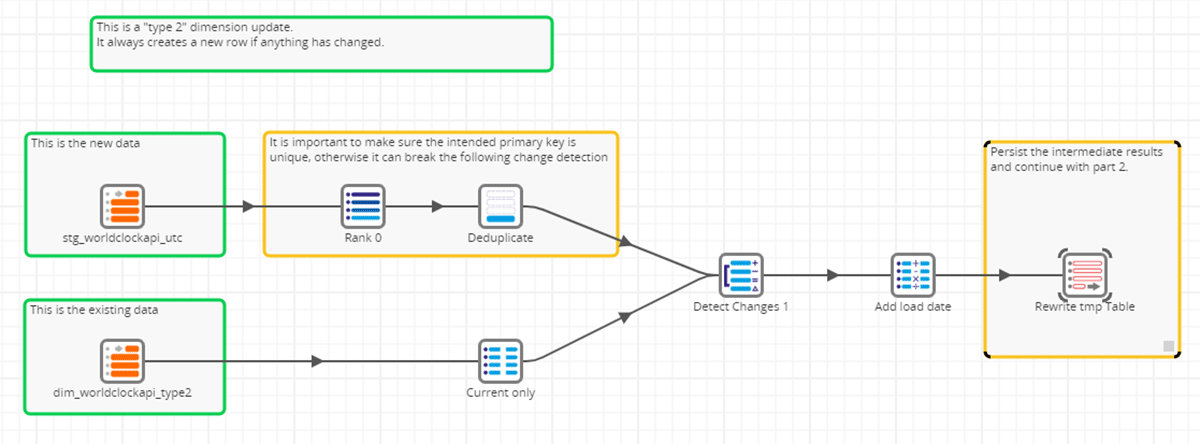
Creating a Delta Table
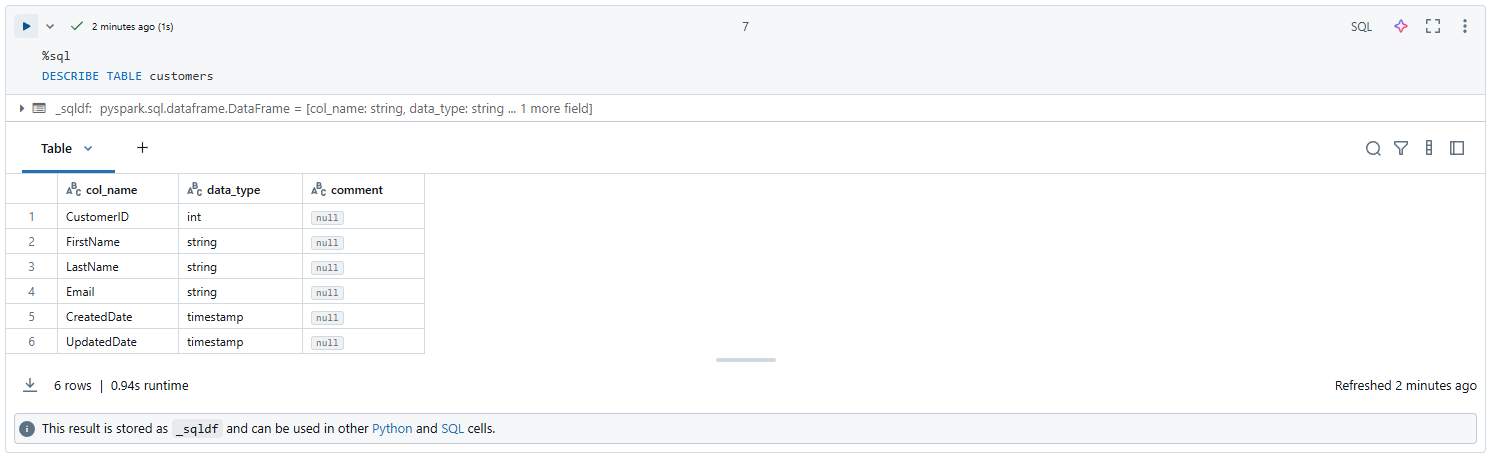
Before we get started, it is IMPORTANT to create an empty delta table first as else, ADF will NOT enable the Change Data Feed. So we create a small notebook in Databricks with the below.
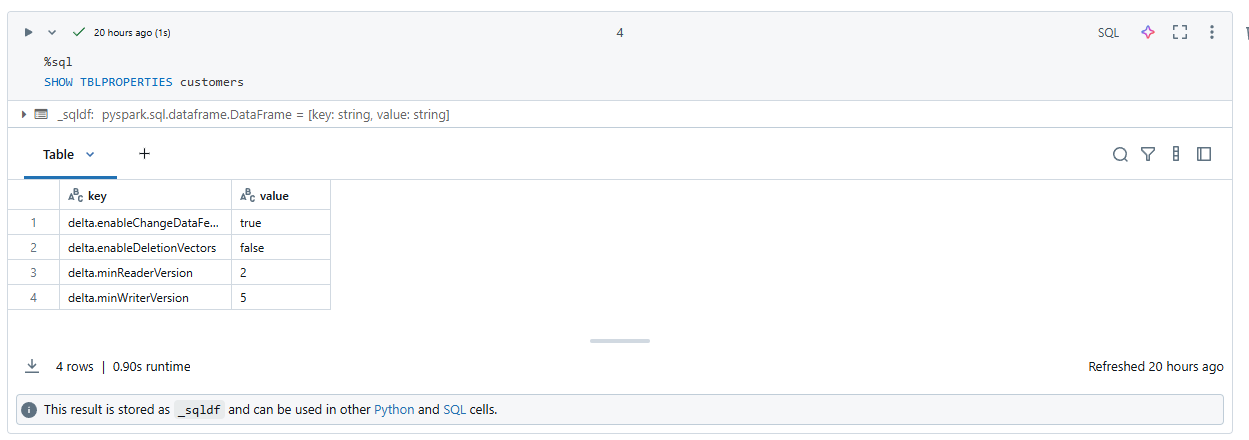
⚠️ Note that we also set theminReaderVersionandminWriterVersionas Databricks uses a new version of Delta lake than Microsoft does. At the time of writing, Microsoft requires 2,5 while Databricks has 3,7. Let's hope Microsoft follows quickly as there are some exciting changes!
⚠️ Besides just setting the versions, we also need to DISABLE deletion vectors, as when setting this, Databricks will automatically default to 3.7
-- Verwijder van de Hive Metastore
DROP TABLE IF EXISTS customers;
-- Maak aan
CREATE TABLE customers
USING DELTA
LOCATION 'abfss://[email protected]/dbo.Customers'
TBLPROPERTIES (
-- Disable deletion vectors as this doesn't work on 2.5
delta.enableDeletionVectors = false,
delta.enableChangeDataFeed = true,
delta.minReaderVersion = 2,
delta.minWriterVersion = 5
)We can then verify that this table was correctly persisted to our storage account and see that the correct reader and writer version were set
💡 Besides the above, we could theoretically as well use this script to do the initial load of the Bronze data (as CDC is incremental and will only sync the changes)
Configuring Azure Data Factory
Completely managed out of the box, Azure Data Factory now offers live CDC (or on a custom interval), syncing data from our SQL Server towards a configured delta table.
We thus create a CDC resource that sinks our Customers table to the previously created delta table.
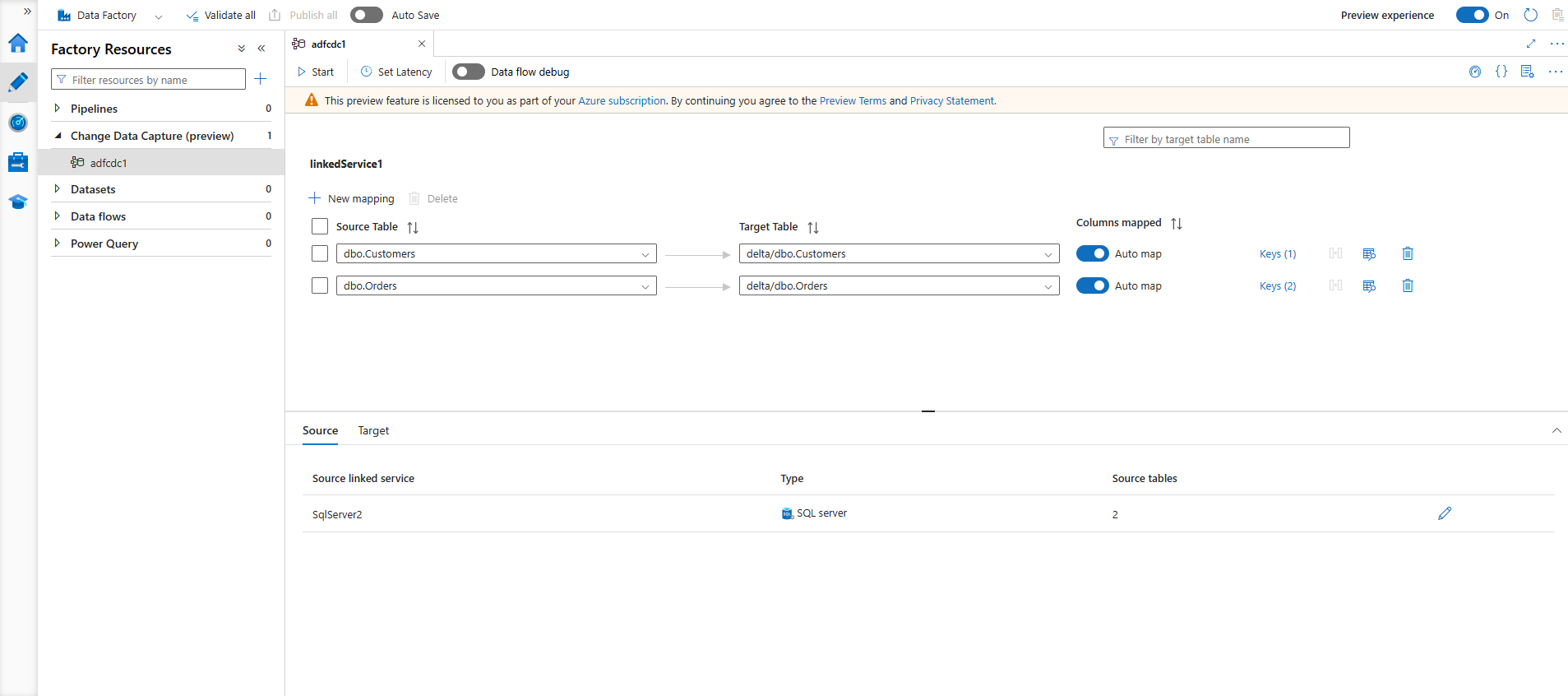
Starting the pipeline shows us that records are being processed! We now have a proper working Bronze load!
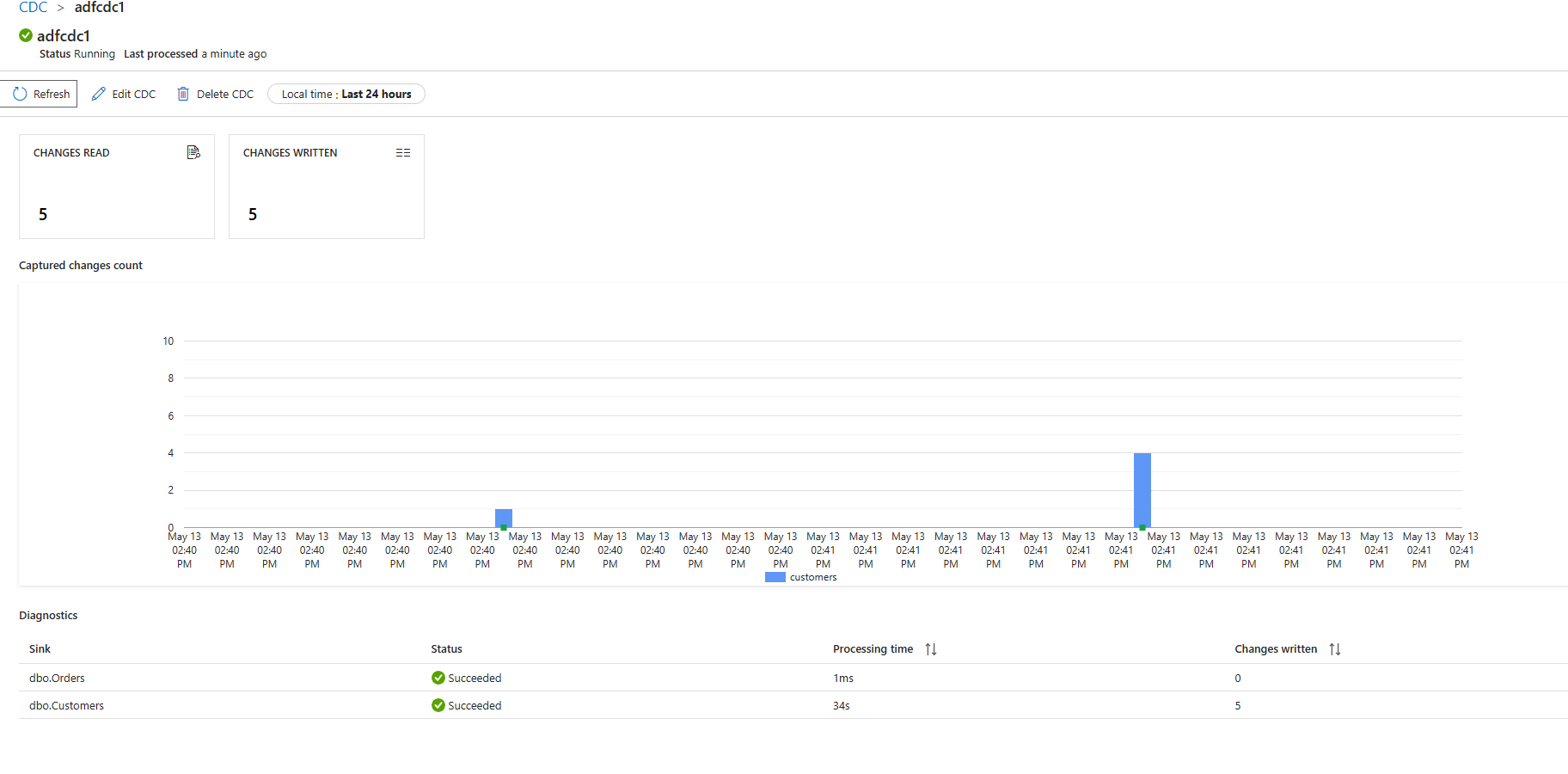
We can verify this data being loaded in our Unity Catalog now!
💡 Do note that the data here is thus not version 1 (as that's the empty schemaless table) but will start at version 2 of our delta table
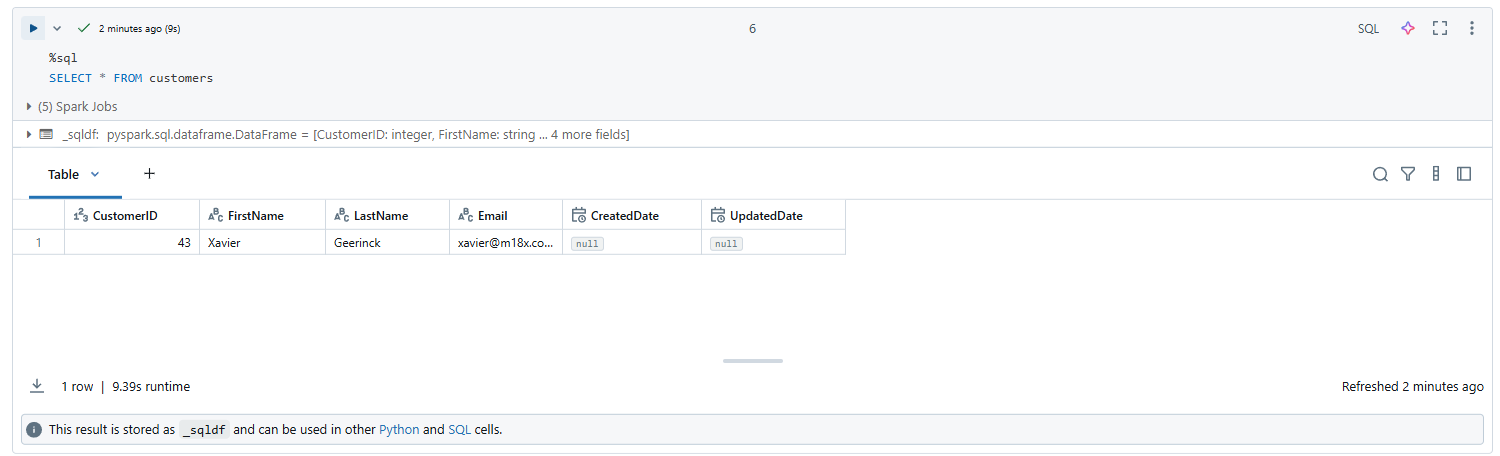
We are now ready with our Bronze setup and can continue on creating the actual pipeline! 🥳
Configuring Databricks
Next up is Databricks itself. Data is being sinked in an Azure Storage account through Azure Data Factory, and we know the changes that happen on that table as we enabled the Change Data Feed.
We can now create the Delta Live Table (DLT) setup that will read the stream of changes and pipe it from Bronze towards Silver to clean and from Silver to Gold for business consumption.
In our case, we see Silver as a SCD 1 (Slowly Changing Dimension) process, which doesn't need to keep track of the changes, while gold is typically a SCD 2 process, where we need to track the changes, or gold can as well be a full rebuild, where we do not load incrementally but rather compute an aggregate.
💡 SCD 1: Do NOT keep track of changes, SCD 2: Keep track of changes
Bronze Stream
# Factory creator of bronze cdc stream readers
# note: since this is a streaming source, the table is loaded incrementally
# Bronze: is the raw CDC stream, does not do deduplication, no SCD logic or no business rules. As raw as possible to preserve original changes for audit, replay or future processing
def create_bronze(table_name, delta_path):
@dlt.table(
name=f"bronze_{table_name}",
comment=f"Bronze - Raw CDC data ingested from ADF for {table_name}",
table_properties={
"quality": "bronze"
}
)
def bronze():
try:
# Return the stream, which starts from the correct version
return (
spark.readStream
.format("delta")
.option("checkpointLocation", f"abfss://[email protected]/checkpoints/{table_name}")
.option("readChangeFeed", "true")
# .option("startingVersion", first_cdf_version)
.option("mergeSchema", "true")
.load(delta_path)
)
except AnalysisException as e:
raise RuntimeError(f"Delta table path does not exist or is not accessible: {delta_path}. Disable it or add it.") from e
for table_name, delta_path in TABLE_CONFIGS.items():
create_bronze(table_name, delta_path)Silver Stream
# Factory creator of silver stream processors
# note: as the bronze table is a stream, silver also needs to be one
# Silver: is the cleansed and validated data, with SCD logic applied
def create_silver(table_name, delta_path):
# Create Streaming Table
dlt.create_streaming_table(
name=f"silver_{table_name}",
comment=f"Cleansed and validated data for {table_name}",
table_properties={
"quality": "silver"
}
)
# Apply changes to silver table using a slowly changing dimension (SCD) type 2 approach
# it creates a new version of the record each time it is updated
# more info: https://www.databricks.com/blog/2021/06/09/how-to-simplify-cdc-with-delta-lakes-change-data-feed.html
# more info: https://www.databricks.com/blog/2023/01/25/loading-data-warehouse-slowly-changing-dimension-type-2-using-matillion.html
# more info: https://docs.databricks.com/aws/en/dlt/cdc?language=Python#example-scd-type-1-and-scd-type-2-processing-with-cdf-source-data
dlt.apply_changes(
target=f"silver_{table_name}",
source=f"bronze_{table_name}",
keys=["CustomerId"],
sequence_by="_commit_version",
ignore_null_updates = False,
apply_as_deletes=expr("_change_type = 'DELETE'"),
except_column_list=["_commit_version", "_commit_timestamp", "_change_type"],
stored_as_scd_type=1 # SCD type 1: keep history of changes
)
for table_name, delta_path in TABLE_CONFIGS.items():
create_silver(table_name, delta_path)Gold Stream
# The gold table will be recomputed each time by reading the entire silver table when it is updated
# aka: it will be rematerialized on each update in silver
# Note: Gold can be incrementally loaded as SCD 2, or aggregately built (full refresh, materialized on each change)
@dlt.table(
name="gold_customers_summary",
comment="Showing all the customers their names",
table_properties={
"quality": "gold",
"delta.autoOptimize.optimizeWrite": "true",
"delta.autoOptimize.autoCompact": "true"
}
)
def gold_customers():
return dlt.read("silver_customers").select(
col("CustomerId"),
concat_ws(" ", col("FirstName"), col("LastName")).alias("Name")
)Running our Pipeline
When we run this pipeline, it will properly startup, showing added and deleted records:

When we now change a record in our SQL Server
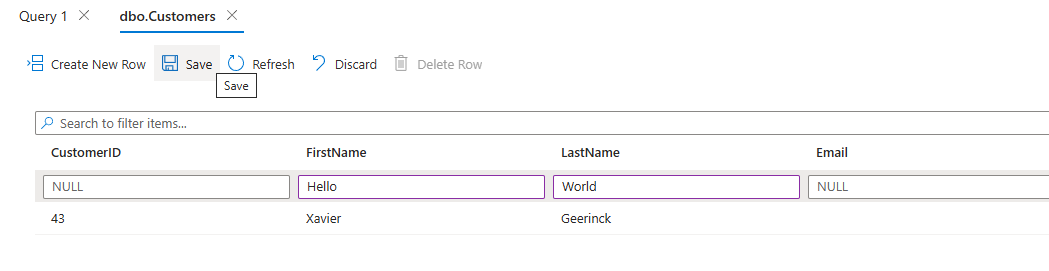
We can see that it is picked up by our CDC process
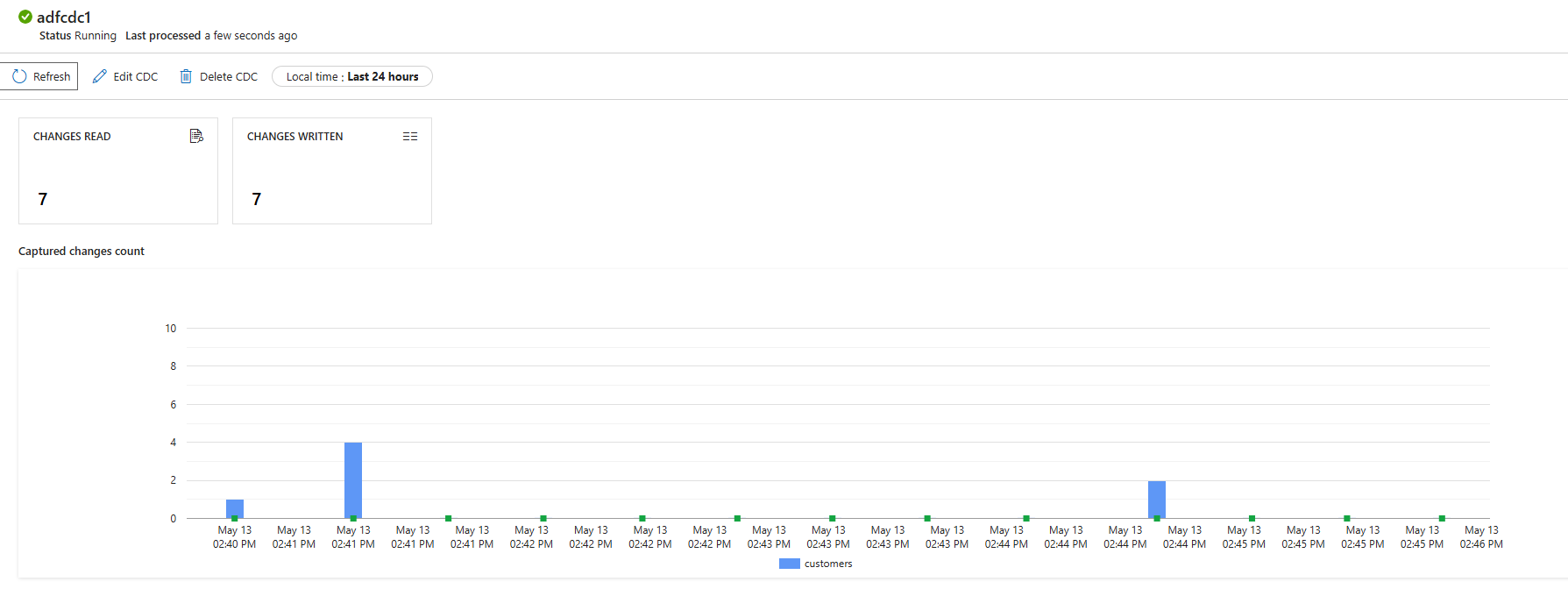
processed towards Bronze (RAW)

which consolidates in Gold processed with the temporary records removed from view
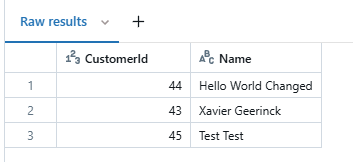
Conclusion
The above requires a change in mindset, going from a previously more batch oriented process, towards now a more real-time oriented process. This process however works with incremental data, making it completely worth it, potentially reducing existing workloads by a huge margin! As we are not running the full pipeline anymore, but rather a small effort of the little chunk of data that changed.
Comments ()