
Roadwork RL - A Multi-Language Reinforcement Learning Environment

After explaining the end-to-end concept of creating a Digital Twin Reinforcement Learning environment I wanted to go into a deeper explanation of how the first part of this can be done.
This is something I have been working on for the last couple of months and decided to call "Roadwork RL". It has also been open-sourced for others to try, so I would love to hear your feedback around this!
Requirements
As in any project, there are some requirements, and a lot of reshaping over the months to make this as easy as possible, satisfying the requirements I had put upfront.
The requirements I decided to use for this project are the following:
- Allow people new to the Reinforcement Learning ecosystem to get started within 5 minutes (after satisfying prerequisites)
- Allow cross-language development
- Allow easy cloud deployment through Kubernetes clusters
Note: you can find the open-sourced code here https://github.com/Xaviergeerinck/Roadwork-RL
Solution
Once requirements have been created, I typically create an architecture to include the different design decisions that have to made. For these requirements, cross-language compatibility is the most difficult one.
As detailed before, Reinforcement Learning consists out of Simulators that are being transformed through actions taken by an agent. Seeing that Simulators have their own unique integration piece often done by Subject Matter Experts and Reinforcement Learning engines have their own unique Algorithms done by Data Scientists, it's interesting to utilize a split between simulator (server) and algorithm (client) through a high-throughput protocol.
For this architecture I decided to utilize the gRPC protocol. This does add some technical complexity compared to HTTP, but is well worth the trade-off due to the gained speed in this project.
After keeping all of the above in mind, I came up with the following architecture detailing the example of the OpenAI Gym and Minecraft RL environment, that are being integrated through an "abstraction" layer specific for that simulator. The SDKs on the language side are then able to communicate with this abstraction layer and execute actions / receive rewards from the simulation environment.
Putting all of this into a diagram results in the following:
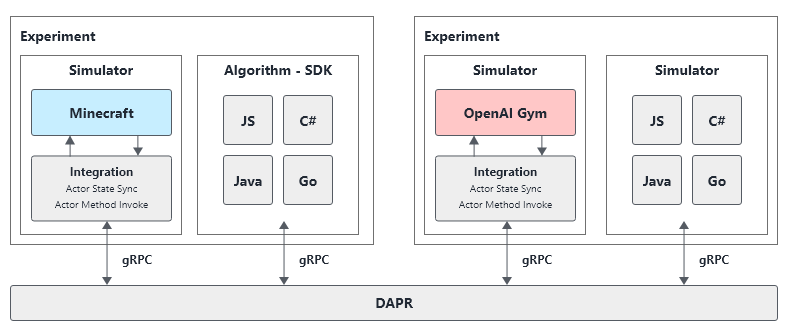
Demonstration
Executing all of the above on the created platform is simple and can be done through a few commands:
# Start OpenAI Gym Server
# Note: this will start the server and keep on running
# this is a Kubernetes "deployment"
sudo ./Scripts/build.sh Servers/openai/ roadwork/rw-server-openai
./Scripts/start.sh rw-server-openai
# Start Python Experiment - CartPole
# Note: this will execute the experiment and stop afterwards
# this is a Kubernetes "pod"
sudo ./Scripts/build.sh Clients/python/experiments/cartpole roadwork/rw-client-python-cartpole
./Scripts/start-client.sh rw-client-python-cartpole
The above will create a deployment in the Kubernetes cluster starting our OpenAI Gym Server. This server will listen on gRPC messages coming in from our Dapr environment. After this, a client is spun up as a pod that will execute a Reinforcement Learning algorithm that solves the Cartpole environment.
After a few minutes of training, our algorithm is done and we an see the following as output:
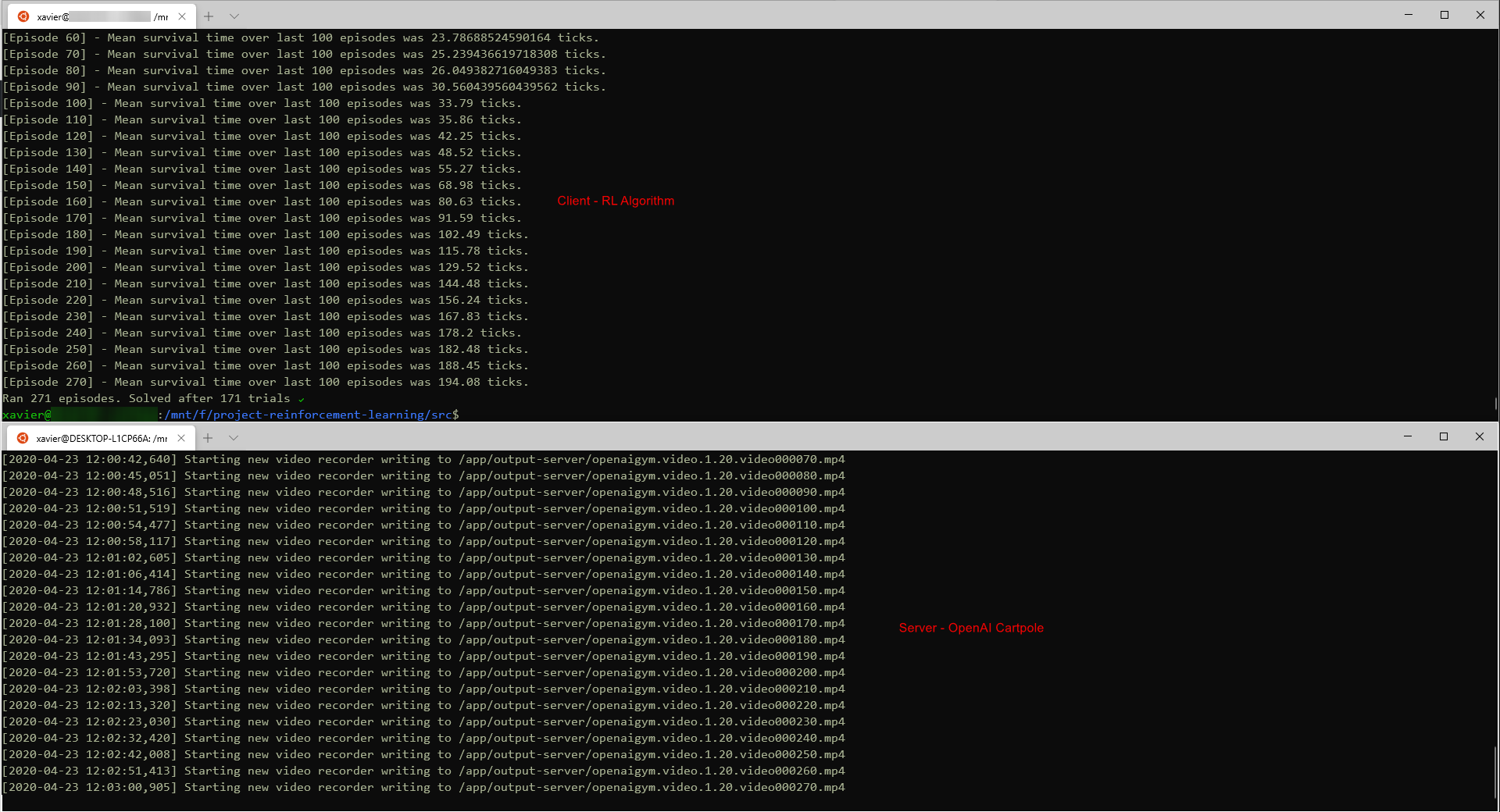
Together with this, video is generated through the OpenAI Server environment. This video is saved on the server cluster and can be fetched through ./Scripts/get-output-server.sh rw-server-openai /mnt/f/test. Which will show us this:
Future Work
The created implementation framework is far from complete, a lot of integrations still have to be written for different simulation environments (e.g. ML Agents, Minecraft, …) while keeping the original code of these environments running (showing the easy integration potential).
Next to that, I would also like this framework to act as a kind of "HPC" cluster. Where experiments can be submitted into a queue and that can be executed when capacity is available (seeing the long running nature of these experiments).
I personally believe that most of the technical foundations are available right now, such that future improvements can be made quite easily and experiments can be ran in the state it is today.
Conclusion
Roadwork RL is a framework specifically created to solve the hard and high entry barrier for Reinforcement Learning. I hope that by creating this framework, more people get interested in this amazing field.
Roadwork RL is definitely a work in progress and has room for growth. Please do share your feedback below, or reach out to me through Social Media for more information / contributing.



Comments ()