
Big Data, the why, how and what - A thought Process and Architecture

One of the most common questions I get when talking with customers, is how they are able to set up a good big data architecture that will allow them to process all their existing data. With as an ultimate goal to perform advanced analytics and AI on top of it, to extract insights that will allow them to stay relevant in the ever faster evolving world of today.
To tackle this issue, I always first start by asking them what their understanding "Big Data" is, because one customer is not the other. One might think that Big Data is just the way they are able to process all their different excel files, while another might think that it is the holy grail for all their projects and intelligence. Well in this article, I want to explain you what Big Data means to me and provide you a thought process that can help you in defining your Big Data strategy for your organization.
Now what is Big Data? Gartner explains it through different V's: "Volume", "Variety", "Velocity", "Veracity", where if you have 2 of the first 3, then you are speaking about Big Data. To quote it in their own words:
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation. - https://www.gartner.com/it-glossary/big-data
For me Big Data is however so much more. It is one thing to be able to speak about it and recognise when you are using, but it's another to implement it in such a way that your whole organisation is able to benefit from it.
Let's tackle 3 of the most common pain points that I see while working with customers:
1. Creating a Centralized Data Lake
When talking with my customers, every time the same question comes up when wanting to start utilizing Big Data. The question of "Where are we going to store it?". But everytime this answer is quite simple: "As centralized as possible". Storing your data in a centralized place will allow you to maintain better control over it. This way you will be able to have a knowledge about your in flows, processing flows as well as your outgoing flows, giving you the power to draw complex analytics from all of this data.
But why can people overlook this then? Well because in the real world it is not as simple as it sounds. Many of the enterprises out there are tens of years old, having processes and structures in place that sometimes date back to these times. Just think about all the enterprises out there that still work in a vertical structure, where teams work in silos and where data belonging to these teams does not cross over to different teams. Resulting in a fragmented data landscape.
Due to this when setting up your centralized data repository, the first part is to perform change management on the organization. Can you go from a vertical structure, to a more horizontal structure where teams work together with each other, and consume the same data repository? More about this in point 3.
While the second part is, how do you correctly store the data coming in from all these different systems in all these different formats and data types. This is what we will look at in point 2.
If you would visualize this thought process, you might end up with something that looks like the following:

2. Utilizing your Data Lake through Landing Zones
So we have all this data coming in, in all their different formats and data types. At first sight, this might look like a bad thing; but actually it isn't. A Data Lake is created for just that, to store data in any kind of format - making it the perfect tool for all your historic needs.
But how do we structure this data? Well, A good practice is to store the data coming in, in different "landing zones". Which are used to not only store your original raw data coming in from your BI systems, videos, … but also to store your processed data - that is processed in such a way that every format and data type is normalized to the same standards that you are used to. Just think about normalizing data so it uses the same date format everywhere. These zones we often call the "raw" and "staging" zones.
Linking these two zones together is just a matter of connecting the correct ETL processes, that pull the data from the "raw" zone, modify it in the way you want, and then puts it in your "staging" zone, ready for consumption by your reporting tools or data warehouses.
An interesting question you may now have is: "But aren't we losing performance if we are going from our original structured data sources towards a data lake, to then go back to a data warehouse"? This is indeed a interesting question that we can only answer by going back to the purpose of a data lake. A Data Lake it's goal is to have a centralized data store, where all our data is collected so that our data scientists are able to perform their jobs on the purest form of source data. But secondly, where our ETL jobs are running, constantly copying the data from the processed "staging" zone towards the target systems. Looking back at these different purposes, we are able to say that even though we might hit a small performance hit, it will be an easy system to control everything happening on our data, resulting in an improved analytics, reporting and even governance process.
3. Correct Internal Governance
As in all good things, there is still a hard thing for everything; this is no exception. The hardest part for creating a centralized data lake is the governance. Now you have have everything in place to pull your data from your different systems towards your data lake and you are able to process this data so that it is available for consumption. But how do you actually work with this across your different teams?
Different teams will work on the data in a data lake, making it necessary to have the correct access control roles in place that will define which users have access to which part of the data lake. Just think about different scenarios, such as a BI specialist who does not need access to the data lake, but rather needs access to aggregated views that we provide them. Or you want to work across regions that allow you to provide row level security on your data, so that the people in the different regions only see the data meant for them. These are all things you will have to think about when creating your Big Data architecture.
Often we see the following roles and how they are configured for these organizations:
- Data Engineer: Your data engineer is in charge of setting up ETL jobs to process data from one landing zone to the other, requiring full access to the data lake.
- Data Scientist: This role has access to the data lake in its purest form through the "raw" landing zone. By providing access to this, data scientists will be able to draw conclusions from your data and build AI models on top of these that could greatly benefit your organization.
- BI Specialist: These people often do not require access to the data itself, but rather to views. It could thus be beneficial to provide access to views created through a system such as Hive that allows your specialist to run simple SQL queries on top of your data, while still providing Row Level Security and everything else that you are used to in terms of security. (Note: Row Level Security is something that needs to be configured correctly, it might sound easy, but it can take a while to configure correctly on unstructured data)
In case you wish extra security and nobody accessing the data lake, you could for example create a subset of your data lake through a simple ETL copy where the different roles are able to play and do everything they wish. With this subset being recreated every night.
Example Architectures
So we defined 3 topics that we need to think about when designing a Big Data architecture, but how does one look in practice now? For this I created 2 architectures that I want to share with you.
The first one is a standard Big Data architecture, allowing you to see how we ingest data from our source systems into a data lake and start serving this. This kind of architecture is what I call a more "slower" architecture, because you might rely on polling systems that will poll every "x" seconds or minutes to see if new data is available. This will happen on the most left part where you get the data from your source systems, as well as on the most right part where data will be pushed towards the consumption layer. However for most use cases this could be fine, it all depends on the question: "How fast do I want data to be available in my consumption layer?".
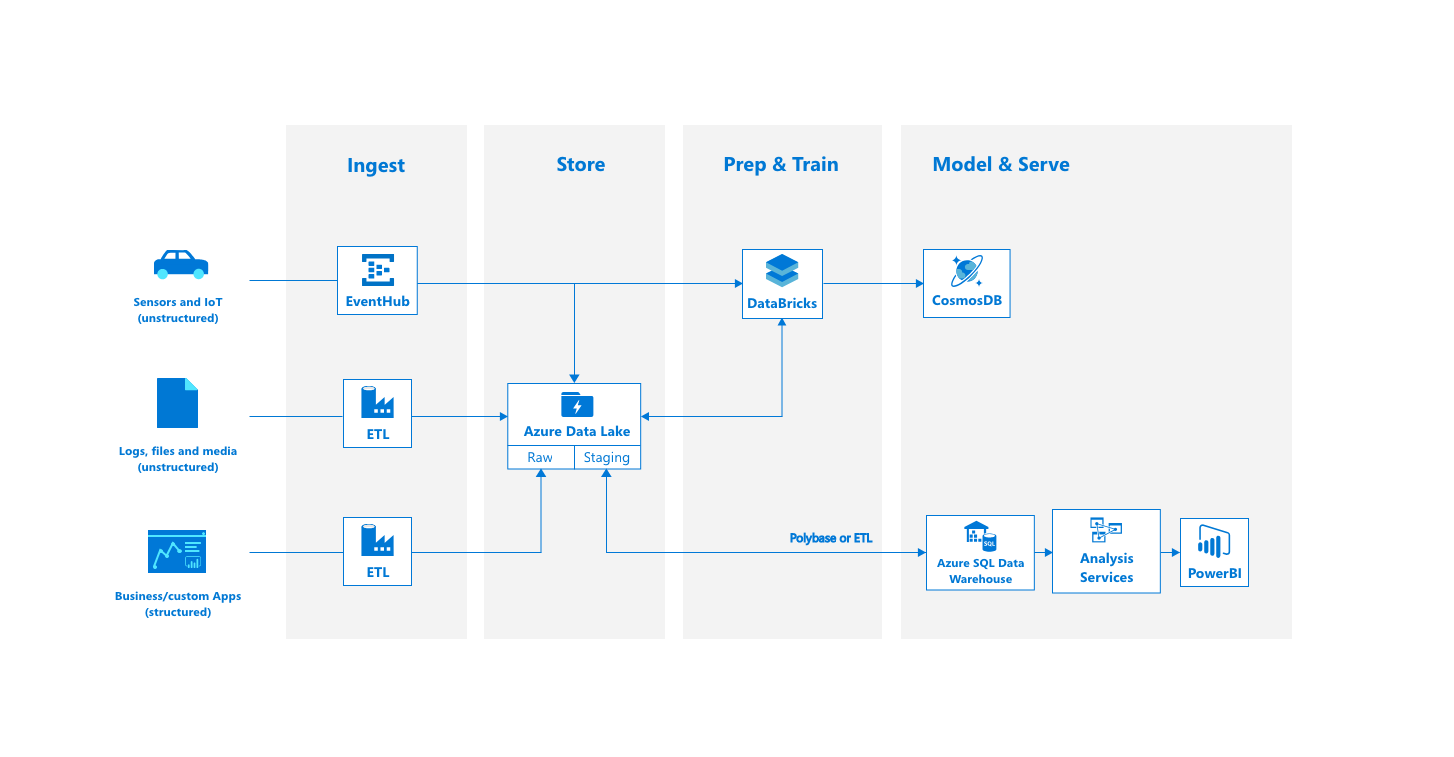
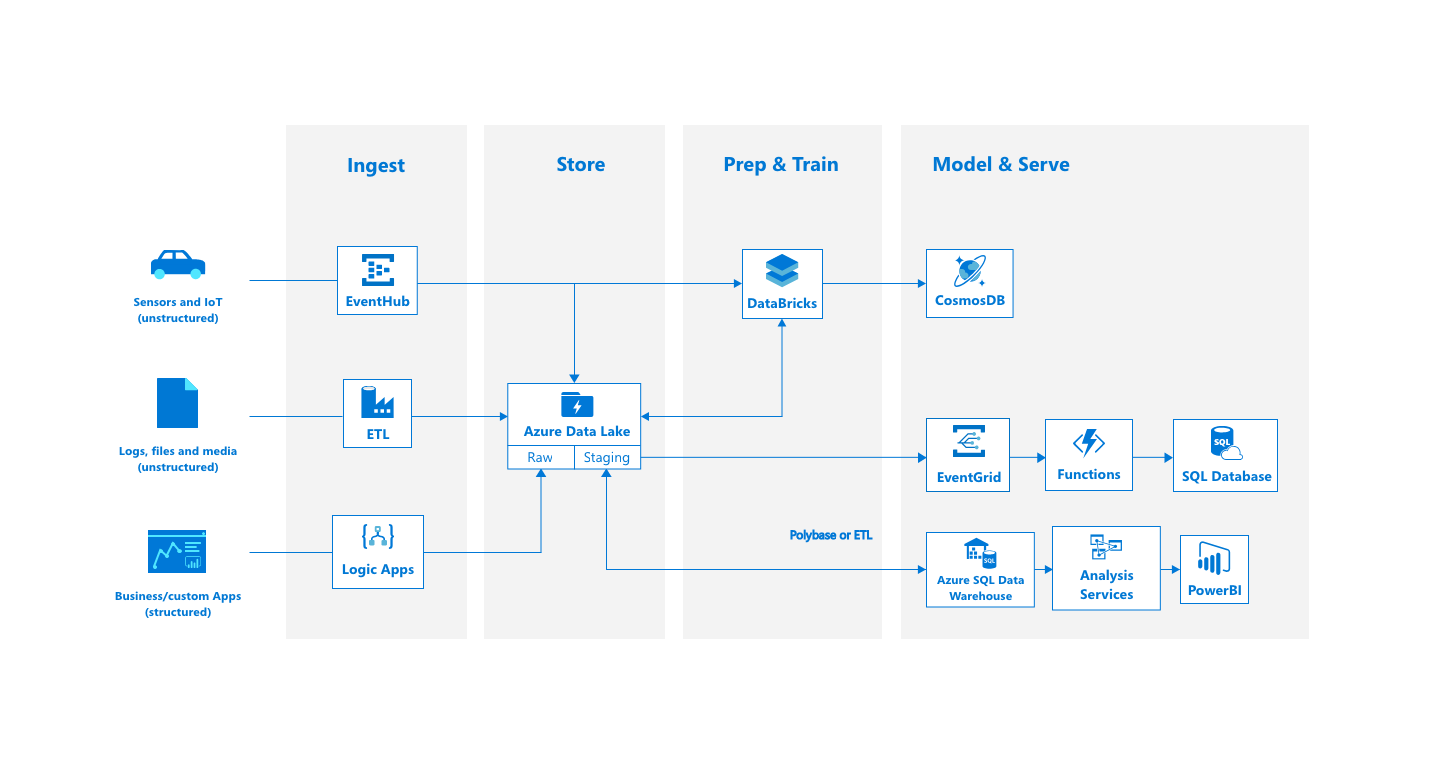
If you however want your data to be accessible almost as soon as it is being put in the systems, then you need to look at more "event-driven" kind of systems. These will work with events that are triggered every time data is made available, rather than having to poll every few seconds or minutes.

Comments ()