
Auto scaling a HTTP triggered application in Kubernetes using Keda

Kubernetes is getting more popular everyday and it's no wonder why! When you are running applications on-premise or in-cloud, the possibility of having the applications in a portable way is a strong one! Removing the friction for scaling-out your application when you are ready for it, or even bursting scenarios.
Use Case
For a use case I have been working on, I have the following requirements:
- 1 HTTP request = 1 Container
- Instance can be up to 1GB of memory
- No pub/sub, but synchronous HTTP request/response!
- Requests execution time can take up to 60 seconds
- I do not want to utilize a pool, but have an auto-scaling system in place
Possible solutions
As in any project, there are multiple paths towards a suitable solution. After researching this a bit, I came across the following tools that looked promising:
- Knative
- This felt like over-kill. It's quite complex to install (though there are tools such as
knctlbut it's outdated) and is quite heavy on the cluster it seems. - Keda
- Super interesting auto scaler, but no HTTP based scaling supported (it's event driven) which I would need.
- Fission
- Interesting! It however seems to keep images in memory (which would be 1GB in memory all the time for us) and auto-scaling is similar to Keda in this sense (it even supports KEDA)
Looking at the above, I was kind of disappointed since no solutions "seemed" to exist. But after a bit more of experimenting and exploration I came across a blog post by Anirudh Garg explaining how you can hook up an Nginx Ingress controller to Keda!
Now the above does solves my issue completely, seeing that I want to transform an async request into a synchronous request (i.e. I want to to get my HTTP request, auto scale the cluster and then return the response). Thus a custom component will have to be written in my case. The blog post however goes into how KEDA can be utilized, which seems to be an excellent fit for me!
Architecture
As always, the most important when creating a new application is to at least draw out a high-level architecture of how the idea will look like. It might sound like a boring and unnecessary job, but I think it helps me a lot in doing a thought excercise that makes me think things through more before wasting time on trying things that won't work. Even if it doesn't work out correctly, you atleast tried 😉
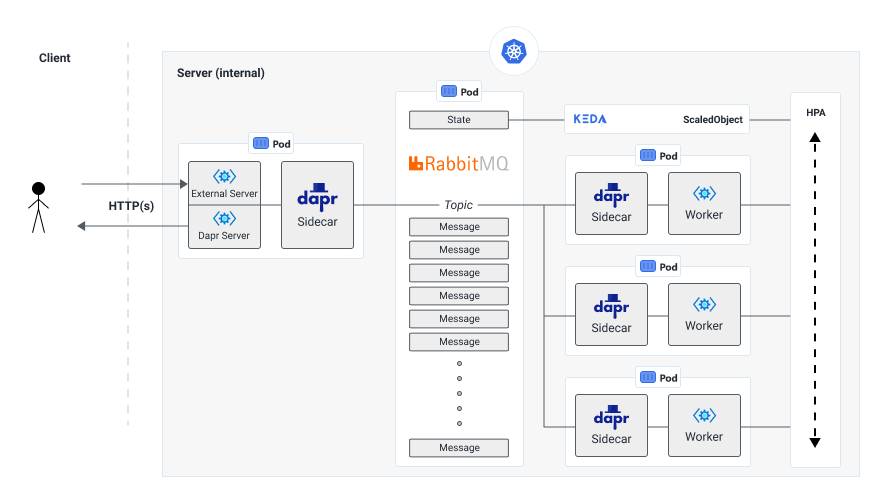
Note: you can find the full source code utilised in this post here: https://github.com/XavierGeerinck/PublicProjects/tree/master/JS/Dapr/AutoScalingHTTP
Solution (Gateway and Worker)
Used Technologies
As for technologies, I decided to settle on the following:
- Dapr
- NodeJS
- Express
- RabbitMQ
- Kubernetes
- KEDA
Prerequisites
Before we get started, make sure the following is available:
- Helm
- Kubernetes cluster with
kubectlmapped to it (Note: locally I just runminikube start --cpus 2 --memory 2048and I'm ready to go)
Installing RabbitMQ
Once Dapr has been installed, we want to set up our queue. As shown in the architecture, we will have an inbound application that puts items on a queue. As soon as these items have been published, a worker will take them and process what it has to do (in our case, returning "Hello World" after a small delay).
To install RabbitMQ, run the following commands:
# ref: https://github.com/bitnami/charts/tree/master/bitnami/rabbitmq/#parameters
# Install repo
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
# Install RabbitMQ
helm install rabbitmq --set auth.username=admin,auth.password=admin,volumePermissions.enabled=true bitnami/rabbitmq
Note: The default username is "user" and the default hostname is "rabbitmq.default.svc.cluster.local:5672" as dictated by the Kubernetes pod defaults of "SVC_NAME.NAMESPACE.cluster.local". The moniker then becomes amqp://user:[email protected]:5672.Important: When you created one before, make sure to delete the old PersistentVolumeClaim else the password won't work (kubectl get pvc)Installing Dapr
The first thing we want to do once we have a Kubernetes cluster ready is to deploy and install Dapr on it. We can do this by running the following command:
# Add helm repo
helm repo add dapr https://dapr.github.io/helm-charts/
helm repo update
# Create namespace dapr-system
kubectl create namespace dapr-system
# Install latest dapr version
helm install dapr dapr/dapr --namespace dapr-system
Installing Dapr Bindings for RabbitMQ
Once Dapr and RabbitMQ have been installed, we can create bindings that will allow us to receive RabbitMQ events on a specific endpoint, as well as send events to RabbitMQ through calling a HTTP endpoint.
For this we create the following .YAML files and apply them on our kubernetes cluster with kubectl apply -f binding-rabbitmq-in.yaml and kubectl apply -f binding-rabbitmq-out.yaml
binding-rabbitmq-in.yaml
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: rabbitmq-worker-input
namespace: default
spec:
type: bindings.rabbitmq
metadata:
- name: host
value: amqp://user:[email protected]:5672
- name: queueName
value: rabbitmq-worker-input
binding-rabbitmq-out.yaml
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: rabbitmq-worker-output
namespace: default
spec:
type: bindings.rabbitmq
metadata:
- name: host
value: amqp://user:[email protected]:5672
- name: queueName
value: rabbitmq-worker-output
Creating our Gateway
On to the hardest part! The gateway! If we take a look again at our architecture, we can see that 2 servers are required here. The reason being that we want to be able to divide external traffic (user request) from the internal Dapr traffic.

We thus create 2 files named src/server-dapr.ts and src/server-external.ts that will handle user traffic and internal traffic.
Note: For the full source code, feel free to check the repository https://github.com/XavierGeerinck/PublicProjects/tree/master/JS/Dapr/AutoScalingHTTP
Note: For testing purposes, it's easier to start-up the instance withdapr run --app-id gateway --app-port 4000 --components-path ../components npm run start:devwhen running it in theAutoScalingHTTP/Gatewayfolder when running from the source code.
Once this is done, we can deploy it through the following Kubernetes YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: d-dapr-autoscaling-http-gateway
spec:
replicas: 1
selector:
matchLabels:
app: dapr-autoscaling-http-gateway
template:
metadata:
labels:
app: dapr-autoscaling-http-gateway
annotations:
dapr.io/enabled: "true" # Do we inject a sidecar to this deployment?
dapr.io/id: "dapr-autoscaling-http-gateway" # Unique ID or Name for Dapr App (so we can communicate with it)
dapr.io/port: "5001" # Port we are going to listen on for Dapr interactions (is app specific)
spec:
containers:
- name: main # Simple name so we can reach it easily
image: thebillkidy/dapr-autoscaling-http-gateway:latest
imagePullPolicy: Always
ports:
- containerPort: 5000 # This port we will expose (external port)
env:
- name: DAPR_HOST
value: "127.0.0.1"
- name: DAPR_PORT
value: "3500"
and run kubectl apply -f deploy/k8s-gateway.yaml with kubectl logs -f deployment/d-dapr-autoscaling-http-gateway -c main to view the logs
Now this is deployed, we can expose the service so we can access it externally:
# Production clusters
kubectl expose deployment d-dapr-autoscaling-http-gateway --type=LoadBalancer --name=svc-dapr-autoscaling-http-gateway --port=80 --target-port=5000
# Development (minikube) cluster
# when running on dev with minikube, we need to expose the svc like this through kubectl port-forward which will open on a random port
kubectl port-forward --address 0.0.0.0 deployment/d-dapr-autoscaling-http-gateway :5000
Creating our Worker
The worker is a bit easier, in this case we will just listen to the incoming work through the input binding that we created. Once work comes in, we then do something (in this case a timeout) and then put it back on the queue! 😀
Kubernetes deployment YAML:
# Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: d-dapr-autoscaling-http-worker
spec:
replicas: 1
selector:
matchLabels:
app: dapr-autoscaling-http-worker
template:
metadata:
labels:
app: dapr-autoscaling-http-worker
annotations:
dapr.io/enabled: "true" # Do we inject a sidecar to this deployment?
dapr.io/id: "dapr-autoscaling-http-worker" # Unique ID or Name for Dapr App (so we can communicate with it)
dapr.io/port: "3000" # Port we are going to listen on for Dapr interactions (is app specific)
spec:
containers:
- name: main # Simple name so we can reach it easily
image: thebillkidy/dapr-autoscaling-http-worker:v0.0.1
imagePullPolicy: Always
ports:
- containerPort: 3000
env:
- name: DAPR_HOST
value: "127.0.0.1"
- name: DAPR_PORT
value: "3500"
and run kubectl apply -f deploy/k8s-worker.yaml
Demo Application
When we now go to the URL of the Gateway and we enter some query parameters (e.g. http://172.28.28.243:38203/?name=Xavier%20Geerinck&timeout=10000) we will see the following result:

Showing what we wanted to achieve! A synchronous HTTP client that works over an Async Queue implementation for offloading the work to workers. But how do we now go and autoscale this? Well this is where KEDA comes in!
Setting up Autoscaling with KEDA
KEDA stands for "Kubernetes Event-Drive Autoscaling" which allows us to monitor certain resources and automatically scale up a deployment based on our needs. It's super easy to set-up and is super powerful in horizontal scalable solutions. So let's get started on configuring this for our set-up!
Installing KEDA
The first thing we should do is to install KEDA. We can simply do this by adding the repository and installing it to our created namespace:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
# Install KEDA v2
kubectl create namespace keda
helm install keda kedacore/keda --version 2.0.0-rc --namespace keda
Configuring KEDA
Once Keda is up and running, we need to configure it to autoscale based on the metrics from our nginx controller. To describe this, we can utilize a YAML configuration that details the different aspects that we want to watch and act upon.
keda-rabbitmq-dapr-http-autoscale.yaml
# https://keda.sh/docs/2.0/scalers/rabbitmq-queue/
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-dapr-autoscaling-http-worker
namespace: default
spec:
scaleTargetRef:
name: d-dapr-autoscaling-http-worker
triggers:
- type: rabbitmq
metadata:
host: amqp://admin:[email protected]:5672 # references a value of format amqp://guest:password@localhost:5672/vhost
queueName: rabbitmq-worker-input
queueLength: "2" # After how many do we scale up?
Once we created this, another kubectl apply -f deploy/keda-rabbitmq-dapr-http-autoscale.yaml will do the trick to configure the autoscaling!
Summary
In this article I showed you how you can utilise technologies such as Dapr and KEDA to make autoscaling workers a piece of cake on Kubernetes! In just a few simple steps we can achieve integrations and monitoring that would else take us a lot of infrastructure work.
I hope you enjoyed this and would love to see your opinions about it! Let me know how I can improve this article further!


Comments ()