
Predicting Instagram Pictures Likes and Comments with .NET Core and ML.NET

For a new fun Project, I wanted to create an Artificial Intelligence model that will allow me to predict the comments and likes of new pictures that a user can post on Instagram based on their own historical data.
Luckily thanks to ML.NET which was released during build 2018, we are able to do this easily through a simple to create pipeline.
What will we be creating? Something like this architecture:
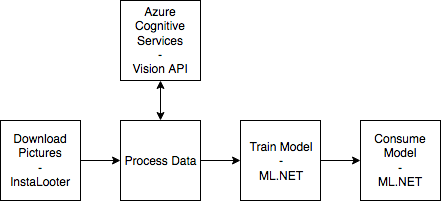
As in every Machine Learning projects, we have to do a few simple steps to go from data towards our eventual prediction:
- Download / Prepare our data ->
Step1.DataPrepfolder - Train our Algorithm based on the data from step 1 ->
Step2.DataTrainingfolder - Consume our model from step 2 ->
Step3.DataPredictionfolder
Resulting in the following folder structure:
root/
Step1.DataPrep/ # NodeJS project so `npm init` to create a package.json
index.js
config/index.js
API/CognitiveServiceVision.js
data/{*.jpg,*.json} # Contains our pictures and metadata
output/result.csv # Contains our CSV created from our pictures
Step2.DataTraining/ # .NET Core solution -> dotnet new console -o Step2.DataTraining
Step3.DataPrediction/ # .NET Core solution -> dotnet new console -o Step3.DataPrediction
Step 1 - Downloading & Preparing our data
For Instagram data we could write our own scraper, or go the easy way and download one from the internet. In my case, I looked on Github and found a nice project called InstaLooter which is written in python and allows us to download instagram pictures + metadata from any user without being authenticated.
# Install InstaLooter
pip install --user instalooter --pre
# Run InstaLooter in our Step1.DataPrep/data folder and download pictures from the <instagram> account
instalooter user instagram -d
After all these pictures are downloaded, you will be able to start preparing them towards a output/result.csv file through a simple node.js script (see below). This script will just go through each image listed in the data/ directory and send them to the Azure Cognitive Service - Computer Vision API to retrieve the tags (which we Rate limit through our Throttling script).
Note: The Instagram API is limited to 1.000 calls, so you will be able to download 1.000 pictures whereafter InstaLooter will time-out.
index.js
const fs = require('fs');
const delay = require('delay');
const config = require('./config');
const API = require('./API/CognitiveServiceVision');
const dataFolder = './data/';
const outputFolder = './output/';
const api = new API(config.thirdParty.cognitiveServices.imageAnalyze.apiKey);
// Get list of images in path with ascending time
let files = fs.readdirSync(dataFolder).filter(i => i.endsWith('.jpg')).sort();
// Go through files, getting the metadata
let csvResult = "shortcode;url;likes;comments;tags;\n"; // init buffer
let count = 0;
let skipped = 0;
// Process each image, getting the tags through Vision Cognitive Service, and checking the json
// Note: Out of order will appear here!
const start = async () => {
// Go through promises, but throttled
const limit = 10; // 10 at a time
// files = files.slice(0, 50);
while (files.length > 0) {
console.log(`[Progress] Processing ${limit} of the ${files.length} images`);
let currentFiles = files.slice(0, limit);
files = files.slice(limit, files.length);
// Prepare promises
let promises = [];
currentFiles.forEach(i => {
promises.push(new Promise(async (resolve, reject) => {
try {
// Get tags
const imageBinary = await api.readImageByPath(dataFolder + i);
const res = await api.analyzeImage(imageBinary);
const tags = res.tags.map(t => t.name).join(",");
// Get JSON content
const file = require(`${dataFolder}${i.replace('.jpg', '.json')}`);
csvResult += `${file.shortcode};${file.display_url};${file.edge_media_preview_like.count};${file.edge_media_to_comment.count};${tags};\n`;
count++;
} catch (e) {
skipped++;
}
// Update progress
console.log(`[Progress] ${count + skipped}/${files.length}`);
return resolve();
}));
})
console.log('awaiting promises');
await Promise.all(promises);
console.log(`Sleeping for 1000ms`);
await delay(1000);
}
// Write result
fs.writeFileSync(outputFolder + 'result.csv', csvResult);
console.log(`Processed ${count + skipped} files, success: ${count} skipped: ${skipped} and saved to ${outputFolder}result.csv`);
}
start();
API/CognitiveServiceVision.js
const fetch = require('node-fetch');
const fs = require('fs');
const util = require('util');
const readFile = util.promisify(fs.readFile);
// Based on https://github.com/Microsoft/BotFramework-Samples/blob/master/StackOverflow-Bot/StackBot/lib/bingsearchclient.js
class CognitiveServiceAnalyzeImage {
constructor(apiKey, opts) {
if (!apiKey) throw new Error('apiKey is required');
this.apiKey = apiKey;
this.baseUrl = "https://westeurope.api.cognitive.microsoft.com/vision/v2.0/";
}
/**
* An util to help you get the binary data of an image
* @param {string} imagePath
*/
async readImageByPath(imagePath) {
const imageBinary = await readFile(imagePath);
const fileData = imageBinary.toString('hex');
const result = [];
for (let i = 0; i < fileData.length; i += 2) {
result.push(parseInt(`${fileData[i]}${fileData[i + 1]}`, 16))
}
return new Buffer(result);
}
async analyzeImageByUrl(imageURL, opts) {
const url = this.baseUrl + "analyze/" + "?"
+ "returnFaceId=true"
+ "&visualFeatures=Tags,Description,Faces,Color"
+ "&returnFaceLandmarks=false"
+ "&returnFaceAttributes=age,gender,headPose,smile,facialHair,glasses,emotion,hair,makeup,occlusion,accessories,blur,exposure,noise";
try {
const response = await fetch(url, {
method: 'POST',
headers: {
"Content-Type": "application/json",
"Ocp-Apim-Subscription-Key": this.apiKey
},
body: JSON.stringify({ url: imageURL })
});
const json = await response.json();
return Promise.resolve(json);
} catch (e) {
return Promise.reject(e);
}
}
async analyzeImage(imageBinary, opts) {
const url = this.baseUrl + "analyze/" + "?"
+ "returnFaceId=true"
+ "&visualFeatures=Tags,Description,Faces,Color"
+ "&returnFaceLandmarks=false"
+ "&returnFaceAttributes=age,gender,headPose,smile,facialHair,glasses,emotion,hair,makeup,occlusion,accessories,blur,exposure,noise";
try {
const response = await fetch(url, {
method: 'POST',
headers: {
"Content-Type": "application/octet-stream",
"Ocp-Apim-Subscription-Key": this.apiKey
},
body: imageBinary
});
const json = await response.json();
return Promise.resolve(json);
} catch (e) {
return Promise.reject(e);
}
}
}
module.exports = CognitiveServiceAnalyzeImage;
When we now look into the output/result.csv file after running node index.js, we will see something like the below, showing that we have our data as we want it for the next step.
shortcode;url;likes;comments;tags;
BWAaIRoA-P7;https://instagram.fbru2-1.fna.fbcdn.net/vp/c5778b6ba5ec4397f23885d0ddc399ec/5C01F7C2/t51.2885-15/e35/19534728_388790801522556_2083772609937276928_n.jpg;1087963;4176;sky,outdoor,water,beach,nature,shore,sunset,clouds,promontory,rock,day,sandy;
BV-mVxyBlvv;https://instagram.fbru2-1.fna.fbcdn.net/vp/1a9647a992a0245b6c3ae652804a5013/5BFB7E57/t51.2885-15/e35/19623518_280508059085489_4094393732026073088_n.jpg;875193;3090;water,outdoor,green,sport,sunset,setting;
...
Step 2 - Training our AI Model
Because we are using ML.NET, our model is straightforward. We will consume our CSV File and parse it by using a TextLoader which will detect our schema from the .csv header.
After that we split our Tags column on the character , and create a OneHotVector with it. This will take all the unique occurrences of our different tags (example: indoor,person,sun,sea,…) and will set a 1 if it occurs in that row. Giving us the following table for the tags given:
||sky|outdoor|water|beach|nature| |-|-|-|-|-|-| |Row #1|1|0|0|0|0| |Row #2|0|1|1|0|0| |Row #3|0|1|1|0|1| |Row #4|0|0|1|0|1|
Now we train with this OneHotVector as our Feature, and tags as a Label, through a StochasticDualCoordinateAscentRegressor as our trainer, saving the model at the end as a simple .zip file.
To run this, just use dotnet run and wait for it to be done, you will see something as in:
PS E:\<MyPath>\Step2.DataTraining> dotnet run
=================== Training Model Likes ===================
Automatically adding a MinMax normalization transform, use 'norm=Warn' or 'norm=No' to turn this behavior off.
Using 2 threads to train.
Automatically choosing a check frequency of 2.
Auto-tuning parameters: maxIterations = 2114.
Auto-tuning parameters: L2 = 0.001.
Auto-tuning parameters: L1Threshold (L1/L2) = 0.25.
Using best model from iteration 74.
Not training a calibrator because it is not needed.
=================== Training Model Comments ===================
Automatically adding a MinMax normalization transform, use 'norm=Warn' or 'norm=No' to turn this behavior off.
Using 2 threads to train.
Automatically choosing a check frequency of 2.
Auto-tuning parameters: maxIterations = 2114.
Auto-tuning parameters: L2 = 0.001.
Auto-tuning parameters: L1Threshold (L1/L2) = 0.25.
Using best model from iteration 48.
Not training a calibrator because it is not needed.
Step 2 - Code
Program.cs
using System;
using System.IO;
using System.Threading.Tasks;
using Microsoft.ML;
using Microsoft.ML.Data;
using Microsoft.ML.Models;
using Microsoft.ML.Trainers;
using Microsoft.ML.Transforms;
using Microsoft.ML.Runtime.Api;
using Step2.DataTraining.Models;
namespace Step2.DataTraining
{
public class Program
{
static string dataPath = "../Step1.DataPrep/output/result.csv";
static void Main(string[] args)
{
// Features: is our input (tags is our input -> based on what do we predict?)
// Labels: is our output (comments is our output -> what do we want to predict?)
Console.WriteLine("=================== Training Model Likes ===================");
CreateModelLikes().Wait();
Console.WriteLine("=================== Training Model Comments ===================");
CreateModelComments().Wait();
}
public static async Task CreateModelLikes()
{
// 1. Load in our data which has the header on the top and we use a csv so ';'
var pipeline = new LearningPipeline();
pipeline.Add(new TextLoader(dataPath).CreateFrom<InstagramData>(useHeader: true, separator: ';'));
// 2. Prepare our Label (what do we want to predict?)
// ColumnCopier: Duplicates columns from the dataset
// -> we need to do this since Label is the column used and ours is called LabelLikes
pipeline.Add(new ColumnCopier(("LabelLikes", "Label")));
// 3. Prepare our features (based on what do we predict?)
// Process Tags in a OneHotVector
// WordTokenizer: splits the text into words using the separator characters
// CategoricalOneHotVectorizer: We create a table of the different tags and set a 1 where the tag appears in our dataset
pipeline.Add(new WordTokenizer("Tags") { TermSeparators = "," });
pipeline.Add(new CategoricalOneHotVectorizer("Tags"){ OutputKind = CategoricalTransformOutputKind.Bag } );
// Prepare Features to train with, in this case with the "Tags" of our instagram pictures
// ColumnConcatenator: Concatenates one or more columns of the same item type
var features = new string[] { "Tags" };
pipeline.Add(new ColumnConcatenator("Features", "Tags"));
// 4. Train our model
pipeline.Add(new StochasticDualCoordinateAscentRegressor());
PredictionModel<InstagramData, PredictedLikes> model = pipeline.Train<InstagramData, PredictedLikes>();
// 5. Save the trained model
await model.WriteAsync("model_likes.zip");
}
// ==================================================================
// Do the same for CreateModelComments..., changing Likes to Comments
// Omitted for readability
// ==================================================================
}
}
Models/InstagramData.cs
// Imports...
namespace Step2.DataTraining.Models
{
// input for prediction operations
// - First 4 properties are inputs/features used to predict the label
// - Label is what you are predicting, and is only set when training
public class InstagramData
{
[Column(ordinal: "0")]
public float Shortcode { get; set; }
[Column(ordinal: "1")]
public float URL { get; set; }
// We set name: "Label" since we will predict this
[Column(ordinal: "2", name: "LabelLikes")]
public float LabelLikes { get; set; }
[Column(ordinal: "3", name: "LabelComments")]
public float LabelComments { get; set; }
[Column(ordinal: "4", name: "Tags")]
public string Tags { get; set; }
}
}
Models/PredictedComments.cs
// Imports...
namespace Step2.DataTraining.Models
{
public class PredictedComments
{
[ColumnName("Score")]
public float Score { get; set; }
}
}
Models/PredictedLikes.cs
// Imports...
namespace Step2.DataTraining.Models
{
public class PredictedLikes
{
[ColumnName("Score")]
public float Score { get; set; }
}
}
Step 3 - Consuming our AI Model
Our model is now trained and created, now we just have to consume it. For this we just load in the zip files through ML.NET and call the .Predict function on the model. To predict likes and comments based on Tags, we load in tags through the CLI and the args parameter in our Main method, resulting in:
PS E:\<MyPath>\Step3.DataPrediction> dotnet run indoor,sun
Predicted likes: 670824.3
Predicted comments: 5451.721
Which is close to the data that we used to train with (looking on sight and comparing values).
Note: We are training with just 700 lines of data, production models have millions of lines of these data and will result in better predictions. Data is always key in AI algorithms.
Step 3 - Code
using System;
using System.Threading.Tasks;
using Microsoft.ML;
using Microsoft.ML.Runtime.Api;
using Step3.DataPrediction.Models;
namespace Step3.DataPrediction
{
class Program
{
static readonly string modelPathComments = "../Step2.DataTraining/model_comments.zip";
static readonly string modelPathLikes = "../Step2.DataTraining/model_likes.zip";
static void Main(string[] args)
{
var tags = args[0];
PredictLikes(tags).Wait();
PredictComments(tags).Wait();
}
public async static Task PredictLikes(string tags)
{
var model = await PredictionModel.ReadAsync<InstagramData, PredictedLikes>(modelPathLikes);
// Predict
var prediction = model.Predict(new InstagramData
{
Tags = tags,
});
Console.WriteLine($"Predicted likes: {prediction.Score}");
}
public async static Task PredictComments(string tags)
{
var model = await PredictionModel.ReadAsync<InstagramData, PredictedComments>(modelPathComments);
// Predict
var prediction = model.Predict(new InstagramData
{
Tags = tags,
});
Console.WriteLine($"Predicted comments: {prediction.Score}");
}
}
}
I hope you enjoyed this article, let me know in the comments below on the results you achieved. For the final source code, feel free to check the repository at: https://github.com/Xaviergeerinck/blog-instagram-correlator


Comments ()